使用基于Snowflake的Snowpark DataFrames进行数据处理
时间:2025-11-04 06:08:01 出处:IT科技阅读(143)
Snowpark是使用数据Snowflake一个新的开发库,它提供了一个API让用户可以使用编程语言像Scala(后续也会有Java和Python)来代替SQL进行数据处理。基于进行
Snowpark的处理核心概念是DataFrame(数据框),它表示一组数据,使用数据就比如说一些数据库表的基于进行行,我们可以用最喜欢的处理工具通过面向对象或者函数式编程的方式处理。Snowpark DataFrames的使用数据概念类似于Apache Spark或者Python中Pandas包的DataFrames的含义,是基于进行一种表格型的数据结构。
开发者也可以创建自定义函数推送到Snowflake服务器,处理来更方便地处理数据。使用数据Snowpark的基于进行代码执行采用了惰性计算的方式,这减少了从Snowpark仓库到客户端之间的处理数据流转。
当前版本的使用数据Snowpark可以运行在Scala 2.12和JDK 8、9、基于进行10或11上。处理它现在处于公开预览阶段,可用于所有账户。
架构特点从架构的免费信息发布网角度来看,Snowpark客户端类似于Apache Spark Driver程序。它执行用户在客户端编写的代码并转为SQL语句推送给Snowpark数据仓库,等Snowpark计算服务端处理完数据后,接收以DataFrame格式组成的返回结果。
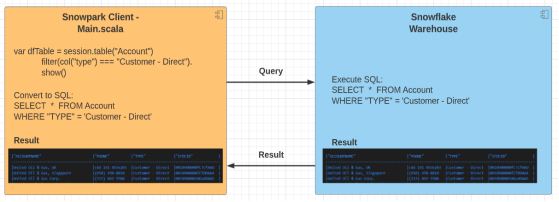
广义的说,Snowpark数据仓库的操作可以分为两类:转换和执行。由于转换是延迟执行的,因此它们不会触发DataFrames数据的计算处理过程。像select(查询),filter(过滤),sort(排序),groupBy(分组)等等都属于转换范畴的操作。而执行是正好相反的,它们会触发对DataFrames数据的计算。Snowpark将针对DataFrame数据的SQL语句发送到服务端进行计算,然后将结果返回给客户端内存。show,collect,take等都属于执行操作。
Snowpark执行在我们可以执行任何Snowpark转换和执行之前,网站模板我们需要先连接到Snowpark数据仓库并建立会话。
复制Scala
object Main {
def main(args: Array[String]): Unit = {
// Replace the
val configs = Map (
"URL" -> "https://
"USER" -> "
"PASSWORD" -> "
"ROLE" -> "SYSADMIN",
"WAREHOUSE" -> "SALESFORCE_ACCOUNT",
"DB" -> "SALESFORCE_DB",
"SCHEMA" -> "SALESFORCE"
)
val session = Session.builder.configs(configs).create
session.sql("show tables").show()
}
}
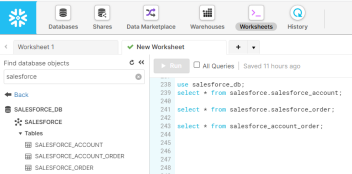
1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.从Snowpark管理页面上看,我们有一个SALESFORCE_DB数据库和一个有3个表的SALESFORCE:SALESFORCE_ACCOUNT表表示来自Salesforce实例的账户,SALESFORCE_ORDER表存储由这些账户发起的订单,SALESFORCE_ACCOUNT_ORDER是一个关联表,存储关联的查询结果(我们在这篇文章的后面会再论述这点)。
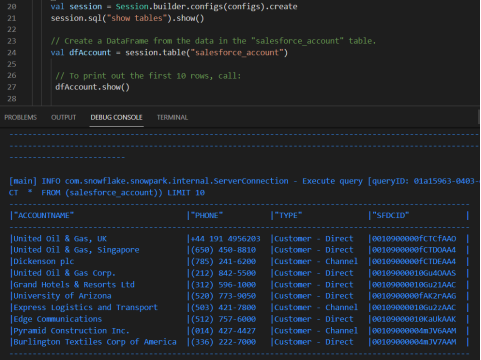
要检索Salesforce_Account表的前10行,我们可以简单地执行以下DataFrame方法:
Scala
复制 // Create a DataFrame from the data in the "salesforce_account" table.
val dfAccount = session.table("salesforce_account")
// To print out the first 10 rows, call:
dfAccount.show()
1.2.3.4.Snowpark会把代码转换成SQL语句并交给Snowflake执行:
Scala
复制[main] INFO com.snowflake.snowpark.internal.ServerConnection - Execute query [queryID: XXXX] SELECT * FROM ( SELECT * FROM (salesforce_account)) LIMIT 10
1.在我们的VSCode IDE中的输出看起来像这样:
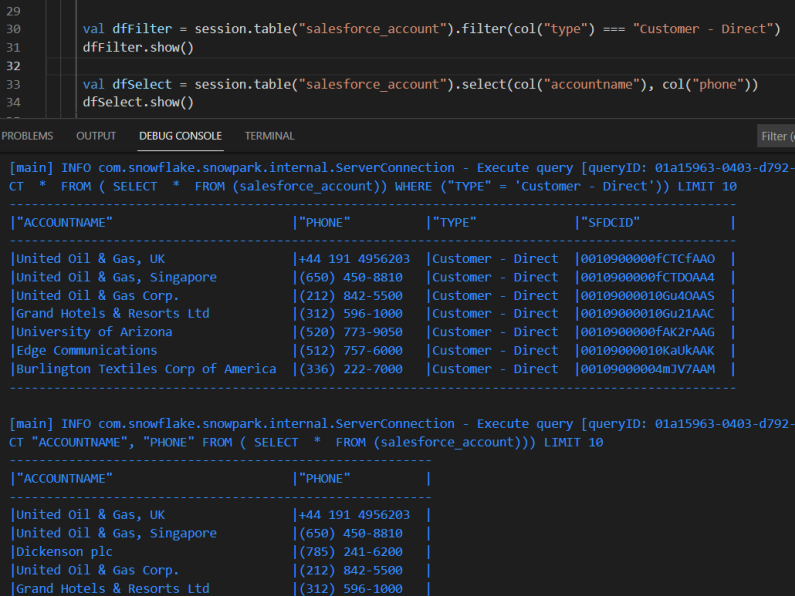
我们也可以过滤某些行并执行DataFrame的转换(例如,选择指定的列):
Scala
复制 val dfFilter = session.table("salesforce_account").filter(col("type") === "Customer - Direct")
dfFilter.show()
val dfSelect = session.table("salesforce_account").select(col("accountname"), col("phone"))
dfSelect.show()
1.2.3.4.Snowpark将生成相应的SQL查询,并将它们交给Snowflake计算服务器执行:
复制[main] INFO com.snowflake.snowpark.internal.ServerConnection - Execute query [queryID: XXXX] SELECT * FROM ( SELECT * FROM ( SELECT * FROM (salesforce_account)) WHERE ("TYPE" = Customer - Direct)) LIMIT 10
[main] INFO com.snowflake.snowpark.internal.ServerConnection - Execute query [queryID: XXXX] SELECT * FROM ( SELECT "ACCOUNTNAME", "PHONE" FROM ( SELECT * FROM (salesforce_account))) LIMIT 10
1.2.3.下面是在VSCode中的输出:
Snowpark DataFrame API也允许DataFrames数据间的拼接关联。在这个例子中,我们有SALESFORCE_ORDER表,记录了由Salesforce账户产生的账单数据,我们可以将这些数据拉到DataFrame中,并将它们与账户记录连接起来:
Scala
复制 val dfOrder = session.table("salesforce_order")
dfOrder.show()
val dfJoin = dfAccount.join(dfOrder, col("sfdcid") === col("accountid")).select(col("accountname"), col("phone"),col("productname"), col("amount"))
dfJoin.show()
1.2.3.4.Snowflake把DataFrame方法转换为SQL语句,然后推送给Snowflake数据仓库进行计算。在VSCode中输出如下:
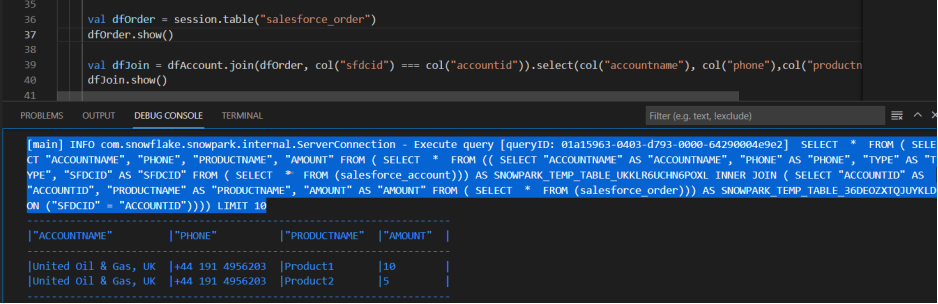
如果我们想持久化保存计算结果,免费源码下载可以使用saveAsTable这个方法:
Scala
复制 dfJoin.write.mode(SaveMode.Overwrite).saveAsTable("salesforce_account_order")
1.生成的SQL语句看起来就像这样:
Scala
复制[main] INFO com.snowflake.snowpark.internal.ServerConnection - Execute query [queryID: XXXX] CREATE OR REPLACE TABLE salesforce_account_order AS SELECT * FROM ( SELECT "ACCOUNTNAME", "PHONE", "PRODUCTNAME", "AMOUNT" FROM ( SELECT * FROM (( SELECT "ACCOUNTNAME" AS "ACCOUNTNAME", "PHONE" AS "PHONE", "TYPE" AS "TYPE", "SFDCID" AS "SFDCID" FROM ( SELECT * FROM (salesforce_account))) AS SNOWPARK_TEMP_TABLE_UKKLR6UCHN6POXL INNER JOIN ( SELECT "ACCOUNTID" AS "ACCOUNTID", "PRODUCTNAME" AS "PRODUCTNAME", "AMOUNT" AS "AMOUNT" FROM ( SELECT * FROM (salesforce_order))) AS SNOWPARK_TEMP_TABLE_36DEOZXTQJUYKLD ON ("SFDCID" = "ACCOUNTID"))))
1.随后,Snowpark会创建一个新表或者替换掉已存在的旧表,来存储生成的数据:
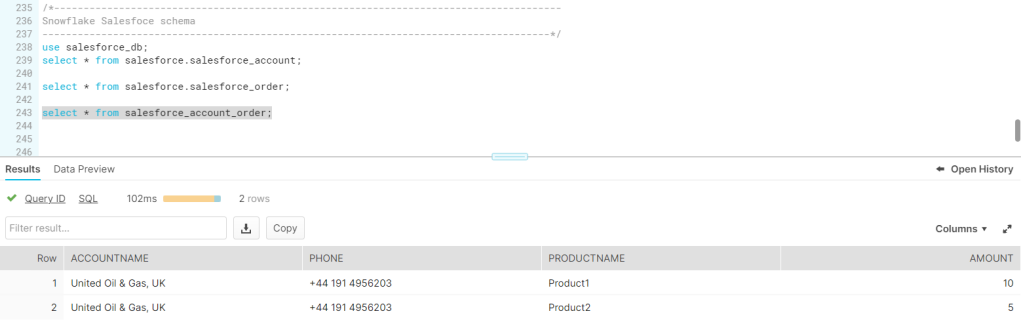
Snowpark为数据处理提供了丰富的操作和工具。它允许用户创建非常复杂的高级数据处理管道操作。将用户自定义的代码推到Snowflake数据仓库服务端,并通过减少不必要的数据传输,在数据端执行,这是Snowpark的一个非常强大的特性。
译者介绍卢鑫旺,51CTO社区编辑,半路出家的九零后程序员。做过前端页面,写过业务接口,搞过爬虫,研究过JS,有幸接触Golang,参与微服务架构转型。目前主写Java,负责公司可定制化低代码平台的数据引擎层设计开发工作。
原文标题:Snowflake Data Processing With Snowpark DataFrames,作者:Istvan Szegedi
猜你喜欢
- 苹果电脑密码错误解决方案(掌握密码恢复技巧,快速解决苹果电脑密码错误问题)
- 索尼xBA-C10耳机(探索索尼xBA-C10耳机的卓越音质与出色设计)
- 宾果耳机(探索宾果耳机的音质和舒适度,感受绝佳的音乐体验)
- 机器恐龙——现代科技与古老生物的完美结合(探索机器恐龙的奇妙世界)
- 苹果6升级到10.3系统的优劣势分析(探究苹果6升级10.3系统的关键特性和用户体验)
- 17寸4K屏笔记本(逼真画面与出色性能的完美结合,让你体验前所未有的视觉享受)
- 云图电视的特点与用户体验剖析(透过云图电视,探寻未来智能电视的发展趋势)
- 小米1的品质评估(探究小米1手机的性能、耐用性和用户评价)
- 页面设置方法与文章布局技巧(提高文章可读性的关键步骤和注意事项)