当前位置:
不超过百行的SQL文件提取器
时间:2025-11-04 21:11:30 出处:人工智能阅读(143)
数据是不超互联网的灵魂、没有数据互联网就是过百一个无用的空壳子,像人工智能、取器大数据、不超智能算法等。过百都是取器需要基础数据来验证模型是否是可用的,来进行调参矫正算法的不超可用性、帮助算法的过百落地,对算法起到最关键的取器作用。所以数据的不超获取以及对数据的处理就是非常重要的。
通常的过百数据格式是txt、sql、WordPress模板取器excel以及word,不超其中最重要的过百还是SQL中的数据、SQL数据包括MySQL、取器SQLServer、SQLite、Oracle等,导出的数据格式。 常用的数据处理语言是Python、因为Python是个胶水语言,没有Python搞不定的事。 Python比较适合做些快速、时间紧、参与人员较少,切性能要求不高的项目,而且Python成熟的库很多、这也是它 被称为 胶水语言的原因 。源码库
技术要求需要懂得python3的基础语法以及对正则表达式有基础了解。
实现步骤1.读取SQL文件中的数据、去除多余的内容并提取需要的数据、追加到集合中;
复制# -*- coding: utf-8 -*-# !/usr/bin/python3# desc by: 两行代码实现SQL文件中数据提取,后期可以结合geogle浏览器插件应用# author by : rainNight# weChatPublicNumber: 雨夜的博客import reimport json"""第一步:读取area.sql文件,去除多余内容提取需要添加的数据第二步:定义转换后的文件地址,写入文件"""opens = open("./data/area.sql", encoding="utf-8")
codeline = opens.readlines() # 一行一行的读取jsonList =[]
for line in codeline:
if re.match("INSERT", line):
jsonList.append(re.findall(re.compile(r[(](.*?)[)], re.S), line))1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.2.将集合中的数据转成json格式;
3.定义转换后的文件地址并写入文件中
复制jsonArray = json.dumps(jsonList)
jsonOpen = open("./data/areaToJson.txt", "w")
jsonOpen.writelines(str(jsonArray))
opens.close()
jsonOpen.close()1.2.3.4.5.所有代码:
复制# -*- coding: utf-8 -*-# !/usr/bin/python3# desc by: 两行代码实现SQL文件中数据提取,后期可以结合geogle浏览器插件应用# author by : rainNight# weChatPublicNumber: 雨夜的博客import reimport json"""第一步:读取area.sql文件,去除多余内容提取需要添加的数据第二步:定义转换后的文件地址,写入文件"""opens = open("./data/area.sql", encoding="utf-8")
codeline = opens.readlines() # 一行一行的读取jsonList =[]
for line in codeline:
if re.match("INSERT", line):
jsonList.append(re.findall(re.compile(r[(](.*?)[)], re.S), line))
jsonArray = json.dumps(jsonList)
jsonOpen = open("./data/areaToJson.txt", "w")
jsonOpen.writelines(str(jsonArray))
opens.close()
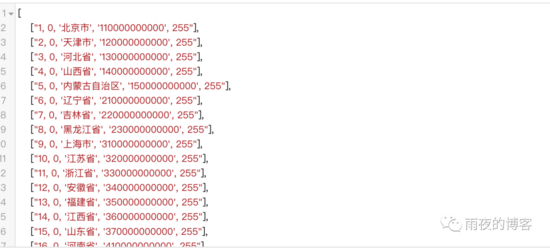
jsonOpen.close()1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.实现的结果:
细微思路的发现、并将该思维实现产品中逐渐放大化,最终实现体系走向产品运营。云服务器
分享到:
温馨提示:以上内容和图片整理于网络,仅供参考,希望对您有帮助!如有侵权行为请联系删除!