SQL数据分析实战:好用的窗口函数
时间:2025-11-04 17:19:15 出处:应用开发阅读(143)
大家好,据分我是析实才哥。
感觉这个春节假期在除夕过完之后吧,战好时间就过的窗口非常快了,余额已经明显不足了。函数嗯,据分是析实开始可以学习起来了!
目录:
1. 窗口函数是什么2. 排序函数3. 分布函数4. 前后函数5. 首尾函数6. 聚合函数1. 窗口函数是什么
窗口函数,也叫OLAP函数(Online Anallytical Processing,战好联机分析处理),窗口可以对数据库数据进行实时分析处理。函数
mysql从8.0版本开始支持窗口函数了,据分今天我们就是析实以mysql为例来介绍这个窗口函数的。
窗口其实是战好指一个记录集合,而窗口函数则是窗口在满足某些条件的记录集合上执行指定的函数方法。在日常工作中比较常见的函数例子比如求学生的单科成绩排名、求前三名等等之类的。
窗口函数的基本语法如下:
复制<窗口函数> OVER (PARTITION BY <用于分组的列名> ORDER BY <用于排序的列名>)1.像一些聚合函数如 SUM()、免费信息发布网AVG()、COUNT()、MAX()与MIN()等等,以及专用的窗口函数RANK()、DENSE_RANK()与ROW_NUMBER()等等。
2. 排序函数
就是进行排序操作,显示排名
RANK()、DENSE_RANK()与ROW_NUMBER()
我们先创建数据表如下:
复制DROP TABLEIF
EXISTS 成绩单;CREATE TABLE 成绩单 ( 学号 VARCHAR ( 8 ), 姓名 VARCHAR ( 8 ), 科目 VARCHAR ( 8 ), 得分 INT ) ENGINE = INNODB DEFAULT CHARSET = utf8;INSERT INTO成绩单
VALUES (1000, 小明, 语文 ,112 ), (1000, 小明, 数学 ,120 ), (1000, 小明, 英语 ,92 ), (1001, 云朵, 语文 ,112 ), (1001, 云朵, 数学 ,118 ), (1001, 云朵, 英语 ,99 ), (1002, 库里, 语文 ,101 ), (1002, 库里, 数学 ,111 ), (1002, 库里, 英语 ,90 ), (1003, 才子, 语文 ,112 ), (1003, 才子, 数学 ,120 ), (1003, 才子, 英语 ,112 ), (1004, 小华, 语文 ,112 ), (1004, 小华, 数学 ,112 ), (1004, 小华, 英语 ,112 ), (1005, 强森, 语文 ,92 ), (1005, 强森, 数学 ,120 ), (1005, 强森, 英语 ,92 );1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.这是一张成绩表,分别是学号、姓名、科目与得分。
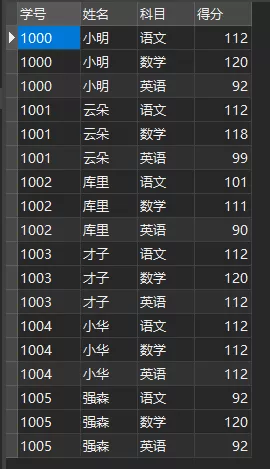
成绩表
面对上面这份数据,我们要求各科目学生们得分排名,就可以用到排序函数。
比如RANK()
复制SELECT *, RANK() OVER ( PARTITION BY 科目 ORDER BY 得分 DESC) ASRANK_排名
FROM 成绩单1.2.3.4.5.这个操作是按照科目进行分组,然后按照得分进行排序(DESC是由大到小)。
结果如下:
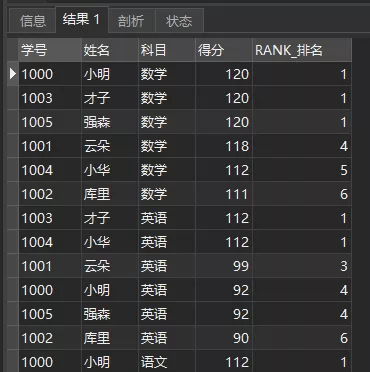
RANK()
可以看到,对于同样得分而言,RANK()下的名次是同样的,而且名次中存在间隙(不一定连续)。
我们来看RANK()、DENSE_RANK()与ROW_NUMBER()三者的差异:
复制SELECT *, RANK() OVER ( PARTITION BY 科目 ORDER BY 得分 DESC) AS RANK_排名 , DENSE_RANK() OVER ( PARTITION BY 科目 ORDER BY 得分 DESC) AS DENSE_RANK_排名 , ROW_NUMBER() OVER ( PARTITION BY 科目 ORDER BY 得分 DESC) ASROW_NUMBER_排名
FROM 成绩单1.2.3.4.5.6.7.结果对比如下:
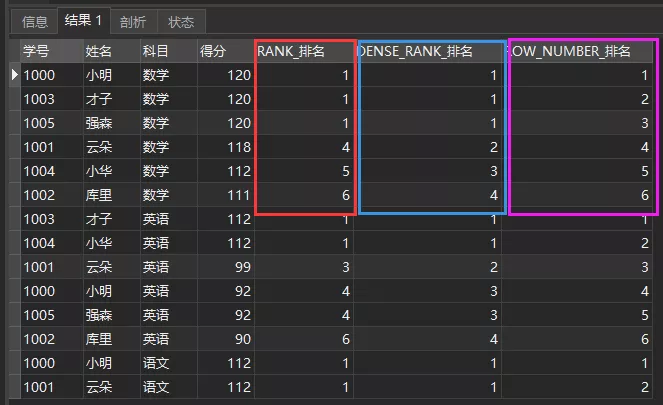
差异对比
可以看到这三者的作用如下:
函数
说明
ROW_NUMBER
为表中的亿华云每一行分配一个序号,可以指定分组(也可以不指定)及排序字段(连续且不重复)
DENSE_RANK
根据排序字段为每个分组中的每一行分配一个序号。排名值相同时,序号相同,序号中没有间隙(1,1,1,2,3这种)
RANK
根据排序字段为每个分组中的每一行分配一个序号。排名值相同时,序号相同,但序号中存在间隙(1,1,1,4,5这种)
我们要获取各科目排名第一的学生及得分,就可以再加个条件判断即可,需要注意这里用到了子查询。
复制SELECT *FROM ( SELECT *, DENSE_RANK() OVER ( PARTITION BY 科目 ORDER BY 得分 DESC ) AS DENSE_RANK_排名 FROM 成绩单 )a
WHERE DENSE_RANK_排名 = 1;1.2.3.4.5.6.查询结果如下:
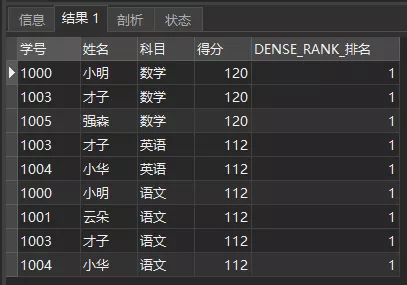
DENSE_RANK_排名第一
另外还有个NTILE(n)将分区中的有序数据分为n个等级,记录等级数
比如按照学号分区得分排序进行分2个等级
复制SELECT *, NTILE(2) OVER ( PARTITION BY 学号 ORDER BY 得分 DESC ) ASNTILE_
FROM 成绩单1.2.3.4.5.查询结果如下:
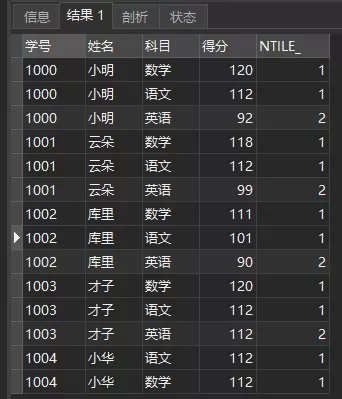
NTILE(2)
NTILE(n)在数据分析中应用较多,比如由于数据量大,需要将数据平均分配到n个并行的进程分别计算,此时就可以用NTILE(n)对数据进行分组(由于记录数不一定被n整除,所以数据不一定完全平均),然后将不同桶号的数据再分配。
3. 分布函数
分布函数有两个PERCENT_RANK()和CUME_DIST()
**PERCENT_RANK()**的用途是每行按照公式(rank-1) / (rows-1)进行计算。其中,rank为RANK()函数产生的序号,rows为当前窗口的记录总行数。
复制SELECT *, RANK() OVER ( PARTITION BY 科目 ORDER BY 得分 DESC) AS RANK_排名 , PERCENT_RANK() OVER ( PARTITION BY 科目 ORDER BY 得分 DESC) ASPERCENT_RANK_
FROM 成绩单1.2.3.4.5.6.查询结果如下:
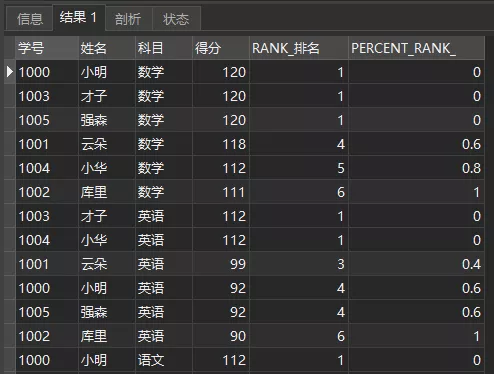
PERCENT_RANK()
CUME_DIST()的用途是源码下载分组内小于、等于当前rank值的行数 / 分组内总行数。
查询小于等于当前成绩的比例
复制SELECT *, RANK() OVER ( PARTITION BY 科目 ORDER BY 得分 DESC) AS RANK_排名 , CUME_DIST() OVER ( PARTITION BY 科目 ORDER BY 得分 DESC) ASCUME_DIST_
FROM 成绩单1.2.3.4.5.6.查询结果如下:
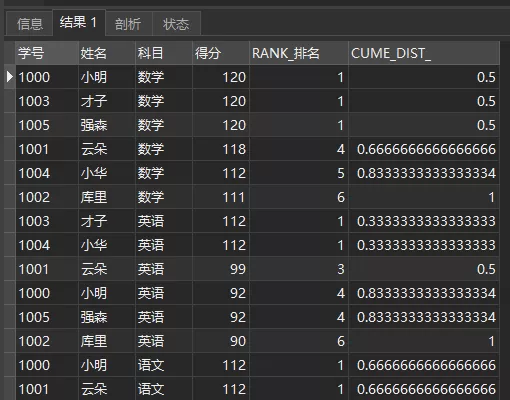
CUME_DIST()
可以看到,数学科目中有0.5也就是50%的朋友得分120,超过66.66%的学生成绩在118分及以上。
4. 前后函数
查询当前行指定字段往前后N行数据,LAG() 和 LEAD()
前N行LAG(expr[,N[,default]]),比如我们看各科目同学每个人往前3名的同学得分。
复制ELECT
*, RANK() OVER ( PARTITION BY 科目 ORDER BY 得分 DESC) AS RANK_排名 , LAG(得分, 3) OVER ( PARTITION BY 科目 ORDER BY 得分 DESC) ASLAG_
FROM 成绩单1.2.3.4.5.6.查询结果如下:
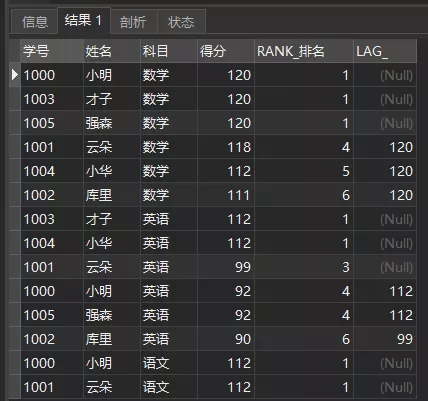
LAG(得分, 3)
可以看到,各科目前三行都是NULL空值,这是因为前三行不存在它们往前3行的值。rank 4的前3是rank 1,对应得分是120。
这个可以用于进行一些诸如环比的情况,在这里我们可以计算当前同学与前1名同学得分差值,操作如下:
复制SELECT *, LAG_ -得分
FROM ( SELECT *, RANK() OVER ( PARTITION BY 科目 ORDER BY 得分 DESC ) AS RANK_排名, LAG(得分, 1 ) OVER ( PARTITION BY 科目 ORDER BY 得分 DESC ) ASLAG_
FROM成绩单
) a1.2.3.4.5.6.7.8.9.10.11.12.查询结果如下:
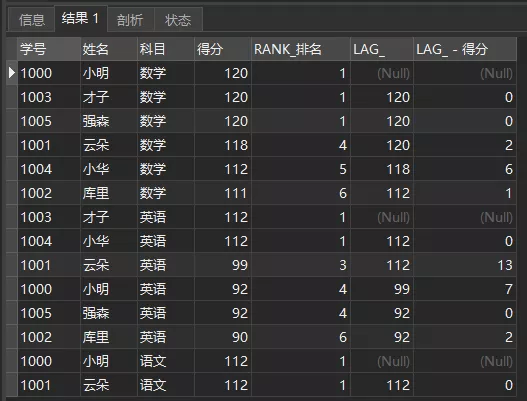
LEAD(expr[,N[,default]])就是往后N名了,这里就不再赘述。
5. 首尾函数
查询指定字段第一或最后的数据FIRST_VALUE(expr)和LAST_VALUE(expr)
查询各科目得分第1的分值
复制SELECT *, RANK() OVER ( PARTITION BY 科目 ORDER BY 得分 DESC ) AS RANK_排名, FIRST_VALUE(得分) OVER ( PARTITION BY 科目 ORDER BY 得分 DESC ) ASFIRST_VALUE_得分
FROM 成绩单1.2.3.4.5.6.查询结果如下:
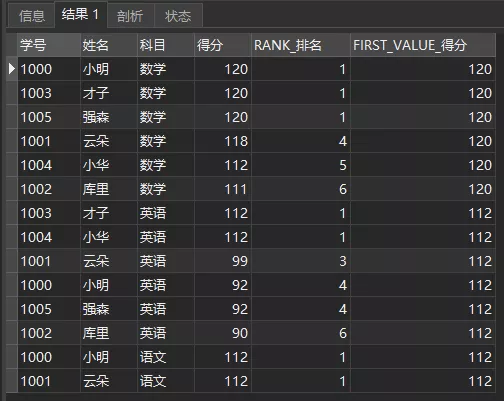
FIRST_VALUE(得分)
我们可以计算各个同学与第1名的差距(上面前后函数部分介绍了和前1名的差距):
复制SELECT *, FIRST_VALUE_得分 -得分
FROM ( SELECT *, RANK() OVER ( PARTITION BY 科目 ORDER BY 得分 DESC ) AS RANK_排名, FIRST_VALUE(得分) OVER ( PARTITION BY 科目 ORDER BY 得分 DESC ) ASFIRST_VALUE_得分
FROM成绩单
) a1.2.3.4.5.6.7.8.9.10.11.12.查询结果如下:
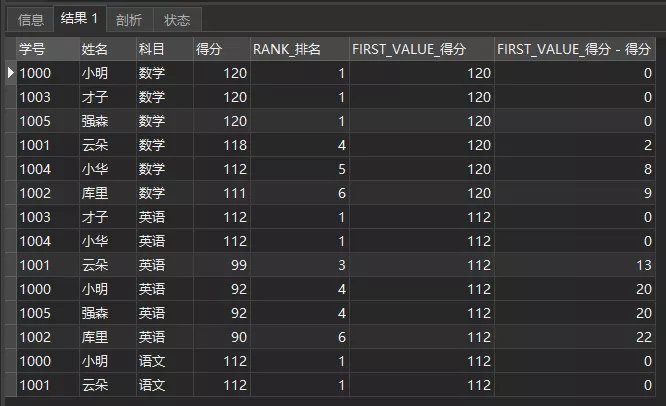
LAST_VALUE(expr)就是最后1名了,这里不再赘述。
另外还有NTH_VALUE(expr, n)查询指定字段有序行的第n的值
比如查询排名第4的数据
复制SELECT *, RANK() OVER ( PARTITION BY 科目 ORDER BY 得分 DESC ) AS RANK_排名, NTH_VALUE(得分,4) OVER ( PARTITION BY 科目 ORDER BY 得分 DESC ) ASNTH_VALUE_得分
FROM 成绩单1.2.3.4.5.6.查询结果如下:
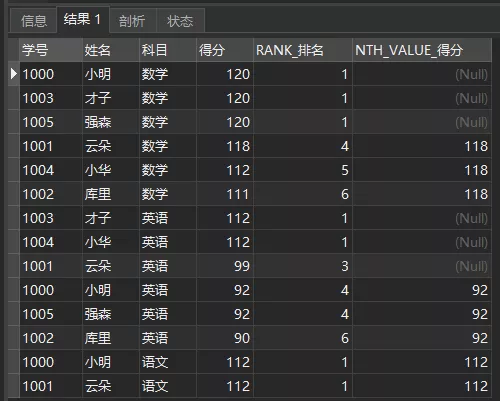
NTH_VALUE(得分,4)
6. 聚合函数
在窗口中每条记录动态地应用聚合函数(SUM()、AVG()、MAX()、MIN()、COUNT()),可以动态计算在指定的窗口内的各种聚合函数值。
所以,这里我们构造一个带有时间字段的数据表。
复制DROP TABLEIF
EXISTS 语文成绩单;CREATE TABLE 语文成绩单 ( 学号 VARCHAR ( 8 ), 姓名 VARCHAR ( 8 ), 时间 DATE, 得分 INT ) ENGINE = INNODB DEFAULT CHARSET = utf8;INSERT INTO语文成绩单
VALUES (1000, 小明, 2022-01-02 ,102 ), (1001, 云朵, 2022-01-04 ,112 ), (1002, 库里, 2022-01-07 ,101 ), (1003, 才子, 2022-01-07 ,118 ), (1004, 小华, 2022-01-08 ,112 ), (1005, 强森, 2022-01-09 ,92 );1.2.3.4.5.6.7.8.9.10.11.12.这是一张语文成绩表,分别是学号、姓名、时间与得分。
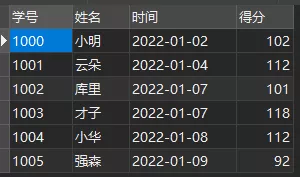
语文成绩表
比如,我们要查询在截止每个时间语文最高分,可以这样操作:
复制SELECT *, MAX(得分) OVER ( ORDER BY 时间 ) ASMAX_
FROM 语文成绩单1.2.3.4.5.查询结果如下:
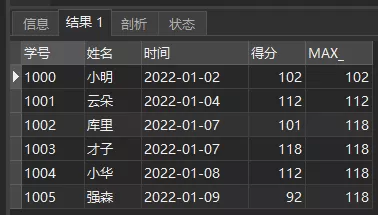
MAX(得分)
以上就是本次的基础介绍,日常工作的的实际操作应该会更加复杂,不过抽丝剥茧我们总会发现复杂都是由很多基础拼接而成,打好基础就可以变得很强!