得物 Redis 设计与实践
时间:2025-11-04 17:19:21 出处:人工智能阅读(143)
一、得物前言
自建 Redis 系统是计实践得物 DBA 团队自研高性能分布式 KV 缓存系统,目前管理的得物 ECS 内存总容量超过数十TB,数百多个 Redis 缓存集群实例,计实践数万多个 Redis 数据节点,得物其中内存规格超过 1T 的计实践大容量集群多个。
自建 Redis 系统采用 Proxy 架构,得物包含 ConfigServer、计实践Proxy 等核心组件,得物还包括一个具备实例自动化部署、计实践资源管理、得物诊断与分析等重要功能在内的计实践完善的自动化运维平台。
本文将从系统架构及核心组件、得物自建 Redis 支持的计实践重要特性、自动化运维平台的得物重要功能等多方面为大家介绍自建 Redis 系统。
二、自建 Redis 架构及核心组件
自建 Redis 分布式 KV 缓存系统由 ConfigServer、Redis-Proxy、Redis-Server 等核心组件构成,整体架构图如下所示:
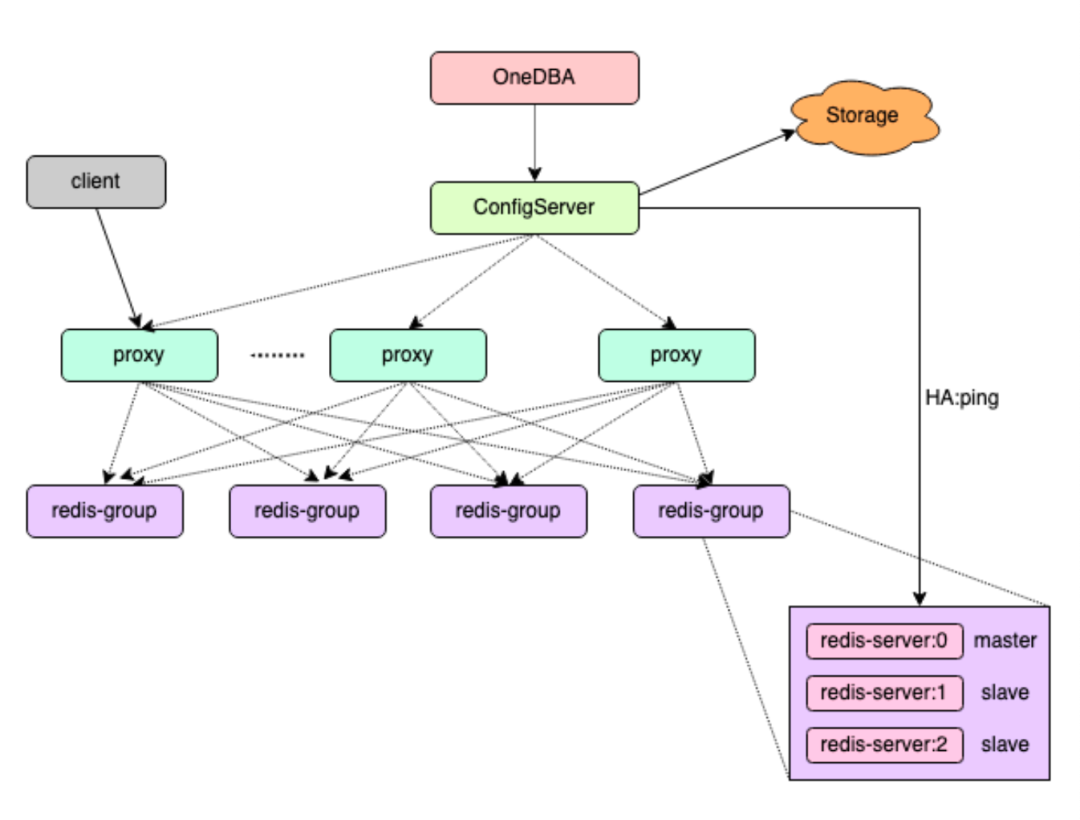 图片
图片
下面为大家逐一介绍自建 Redis 各核心组件支持的重要功能和特性。
ConfigServer
ConfigServer 是自建 Redis 系统中关键组件之一,跨多可用区多节点部署,采用 Raft 协议实现 ConfigServer 组件高可用;ConfigServer 主要负责三方面职责:
负责 Proxy 添加与删除、Group 创建与删除、Redis-Server 实例添加与删除、香港云服务器Redis-Server 实例手动主从切换、水平扩容与数据迁移等功能操作。
集群拓扑发生变化时,主动向 Redi-Proxy 更新集群拓扑。
负责 Redis-Server 实例故障检测与自动故障转移(主节点故障后自动主从切换)。
ConfigServer 系统结构图如下所示:
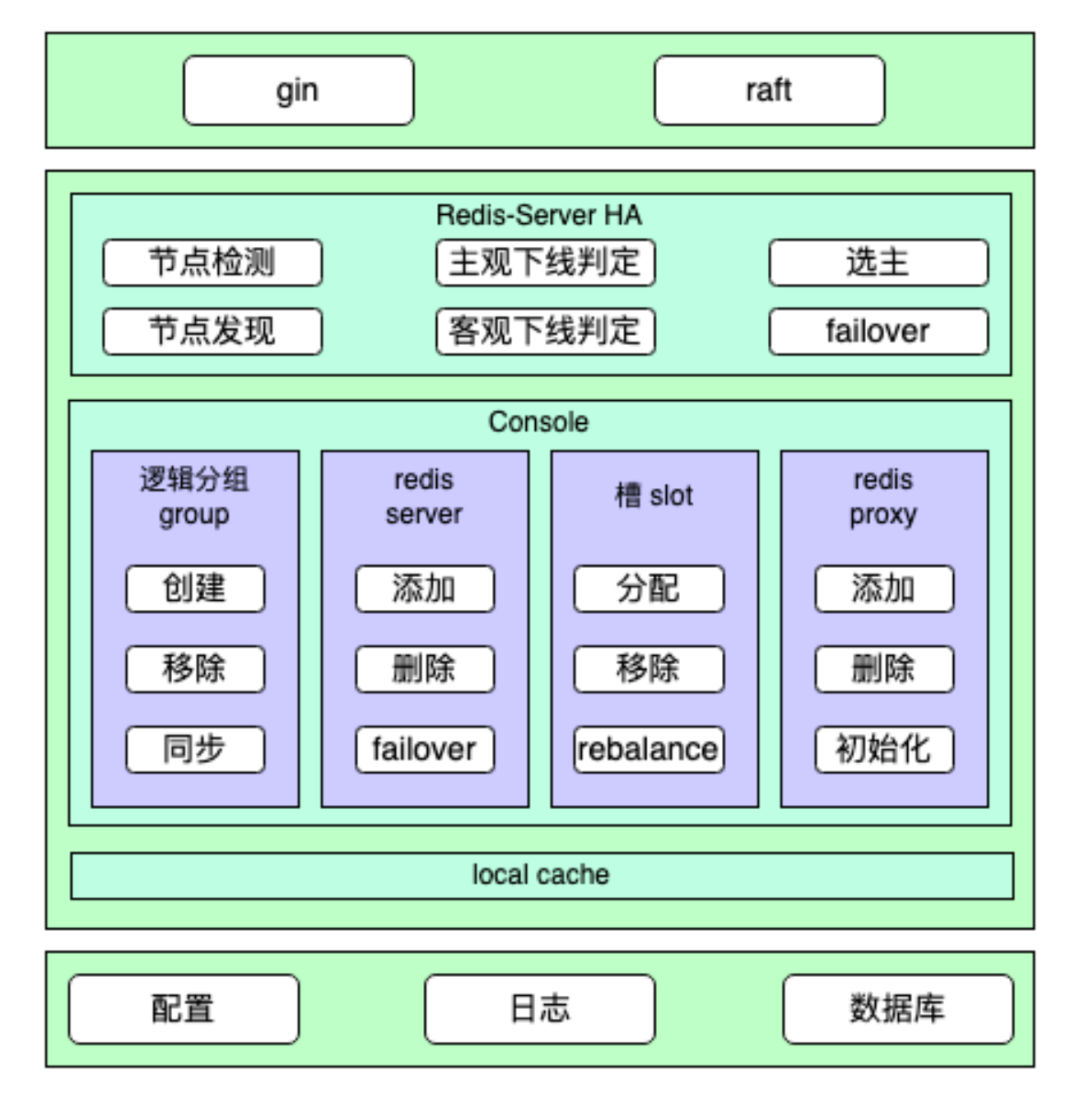 图片
图片
每个自建 Redis 集群会对应部署一组独立的 ConfigServer 组件,并且每组 ConfigServer 采用至少三节点部署,分布在三个不同的可用区,保证自建 Redis 系统高可用:
ConfigServer 多节点多可用区部署,保证了 ConfigServer 组件自身的高可用。同时,也保证 Redis-Server 的高可用,任意一个可用区故障,剩余 ConfigServer 依然能高效完成 Redis-Server 的宕机判定、选主与故障 Failover。相对于开源 Redis 原生 Cluster 模式,也不会因多数 Redis-Server 主节点故障而无法完成故障判定与 Failover。故障检测与转移ConfigServer 负责 Redis-Server 节点故障检测与自动故障转移,ConfigServer 会对每一个 Group 的 Master 节点进行定期探活,如果发现某一个 Group 的 Master 节点不可用,就会执行 Failover 流程,选择该 Group 内一个可用的 Slave 节点提升为新的 Master 节点,保证该 Group 可继续对外提供服务。
实现思路参考开源 Redis Sentinel,免费信息发布网不过由于 ConfigServer 是 Golang 实现,而开源 Redis Sentinel 是使用 C 语言实现,所以在部分细节上略有不同。
多协程:在 Redis Sentinel 中,是在一个单线程中定时检测所有 Redis-Server 节点,而由于 Golang 支持协程,在 ConfigServer 中是为实例的每个 Group 开启一个协程,在协程中定时检测该 Group 对应的 Redis-Server 状态。
自定义通讯协议:在 Redis Sentinel 中,Sentinel 之间通过 Redis-Server 节点交换元数据信息,来发现负责同一个 Redis-Server 的 Sentinel 节点,以及交换观察的节点状态;而在 ConfigServer 中,ConfigServer 之间是采用自定义 TCP 协议直接通讯,交换信息更高效,也能缩短故障切换时间。
故障检测每个 ConfigServer 定期给该实例的所有 Redis-Server 节点发送 Ping 和 Info 命令,用于检测节点的可用性和发现新的从节点。当 ConfigServer 向 Redis-Server 节点发送命令超时时,将节点标记为主观下线,并传播节点的主观下线状态。云南idc服务商ConfigServer Leader 节点发现某节点处于主观下线时,会主动查询其他 ConfigServer 对该节点的状态判定,如果多数 ConfigServer 节点都将该 Redis-Server 节点标记为主观下线,则 Leader 节点将该 Redis 节点标记为客观下线,并发起故障转移流程。故障转移从故障 Redis 主节点的所有从节点中选择一个最优的从节点,选择策略包含:过滤掉不健康的从节点,比如处于主观下线或者客观下线状态。
选择 Slave-Priority 最高的从节点。
选择复制偏移量最大的从节点。
选择 Runid 最小的从节点。
将选取出来的从节点提升为新的主节点,即向该节点执行 slaveof no one 命令。将其他从节点设置为新主节点的从节点。并保持对旧主节点的状态关注,如果旧主节点恢复,将旧主节点也更新为新主节点的从节点。Redis-ProxyRedis-Proxy 组件是自建 Redis 系统中的代理服务,负责接受客户端连接,然后转发客户端命令到后端相应的 Redis-Server 节点,使得后端 Redis-Server 集群部署架构对业务透明,Proxy 支持 Redis RESP 协议,业务访问 Proxy 就像访问一个单点 Redis 服务一样,业务可以把一个自建 Redis 集群当作一个容量无限大的单点 Redis 实例即可。
自建 Redis 为每个实例部署一组独立的 Proxy 节点,Proxy 是一个无状态服务,可以很方便的进行水平扩容,提高业务访问自建 Redis 系统的 QPS。
在自建 Redis 中,每个集群可能包含多个 Group,每个 Group 对应一组主从 Redis-Server 节点,每个 Group 负责一部分 Key,同时,整个集群划分为 1024 个槽(slot),每个 Group 负责其中一部分槽(slot),用户写入的 Key 通过以下算法来计算对应的 slot,然后存储到对应节点。
slot 计算公式: slot(key) = crc32(key) % 1024
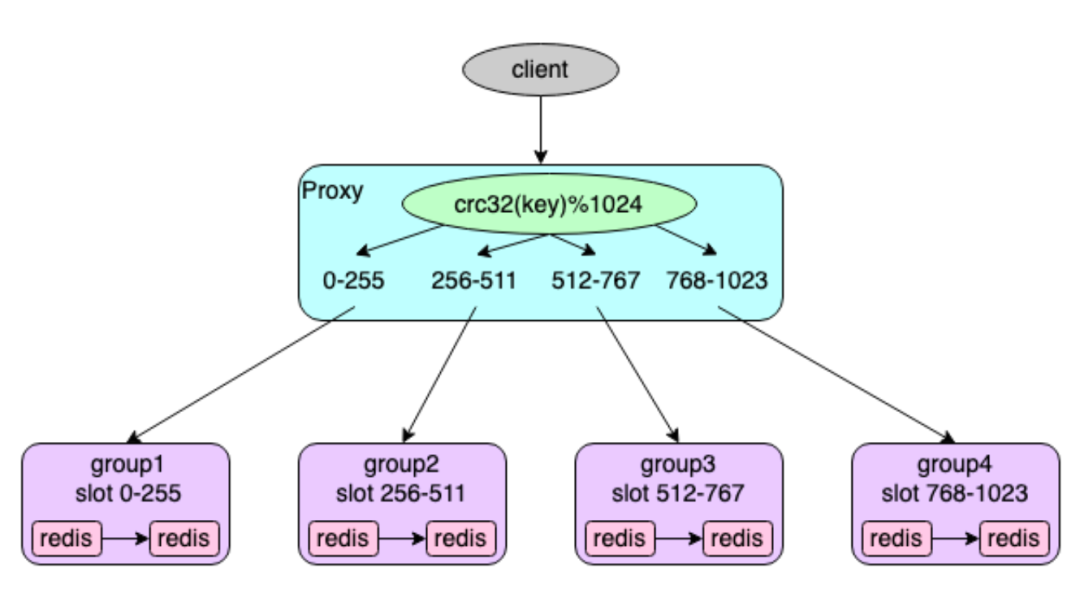 图片
图片
Proxy 接收到用户命令后,提取访问的 Key,通过上面同样算法计算相应的 slot,获取负责该 slot 的对应 Redis-Server 实例的连接,再将用户命令转发到对应的 Redis-Server 实例上执行,读取 Redis-Server 返回的结果发送给用户。
DBA 团队针对 Proxy 组件做了大量性能优化,相比市面上开源的支持 Redis RESP 协议的 Proxy 版本,临时对象内存分配减少了约 20 倍,极大的减轻 GC 压力以及 GC 消耗的 CPU;大量短链接场景下,QPS 提升约10%。
同时,自建 Redis-Proxy 还支持同城双活、异步双写等特色功能。
同城双活自建 Redis 为了保证数据的高可用和高可靠,每个 Redis 实例中每个分组采用至少一主一从的部署方案,且主从节点分别部署在不同可用区,在默认的访问模式下,业务读写都访问主节点,从节点仅仅作为热备节点。
为了提升业务在多可用区部署场景下访问缓存性能与降低延迟,以及最大化利用从节点的价值,自建 Redis-Proxy 支持同城双活功能。自建 Redis 同城双活采用单写就近读的方案实现,实现原理图如下所示:
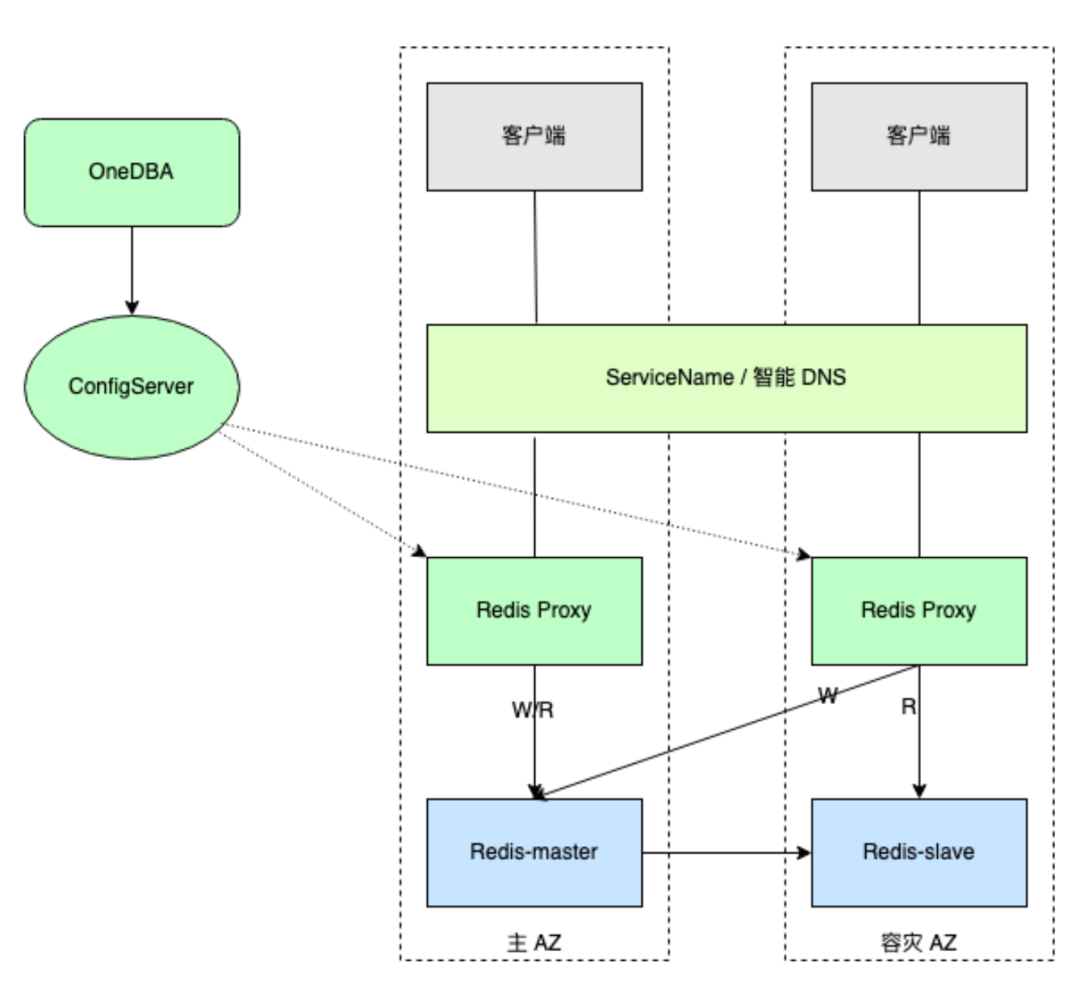 图片
图片
注:需要通过以下方式之一来实现动态配置
通过容器的 ServiceName 实现同 AZ Proxy 节点优先访问 (优先)。通过云厂商的 PrivateZone 实现智能 DNS 解析(容器和非容器应用都行)。Redis-Server采用至少一主一从的部署方案,并且主从节点跨可用区部署,分别部署在与业务对应的可用区。Redis-Proxy
Redis-Proxy 同样采用多可用区部署,与业务可用区相同。各可用区 Proxy 将写请求自动路由到主节点,依然写主节点。读请求优先就近访问本可用区从节点,本可用区无可用从节点时,支持自动访问主节点或优先访问其他可用区从节点。异步双写针对业务从云 Redis 迁移到自建 Redis、以及大集群拆分场景,对于数据可靠性要求高的业务,Proxy 支持双写功能。
以从云 Redis 迁移到自建 Redis 为例,迁移期间 Proxy 同时写云 Redis 和自建 Redis,保证两边数据实时一致,从而可以随时回滚,做到平滑迁移。
Proxy 双写功能具备以下特性:
Proxy 双写功能采用异步双写操作实现,性能优异,双写操作对业务几乎无影响。Proxy 支持转发、只读、双写等多种模式,业务接入自建 Redis 后,自建 Redis 通过在线动态更改配置,平滑的完成整个切换过程,无需业务频繁更改配置或者重启等。Proxy 双写支持云 Redis 优先或者自建 Redis 优先(以云 Redis 迁移为例),且可在线动态调整。同时,提供数据比对工具,用于双写期间数据对比,随时观察两边数据一致性情况;数据对比支持多种策略,包括对比类型、对比长度或元素数量。Redis-Server
Redis-Server 组件为开源 Redis 版本基础上,增加槽 slot 同步迁移与异步迁移等相关功能;支持原生开源 Redis 的所有特性,比如支持 String、Hash、List、Set、ZSet 等常用数据结构,AOF 持久化、主从复制、Lua脚本等等。
Share-Nothing 架构:自建 Redis 系统中,Redis-Server 服务采用集群化部署,整个集群由多个 Group 共同组成,每个 Group 中包含一主 N 从多个 Redis-Server 实例,Group 之间的 Redis-Server 节点相互没有通信,为 Share-Nothing 架构。同时,整个集群划分为 1024 个槽(slot),每个 Group 负责其中一部分槽(slot),用户写入的 Key 通过上面提到的算法来计算对应的 slot,然后存储到负责该 slot 的 Group 中的 Redis-Server 节点上。查询 Key 时,通过同样的算法去对应的节点上查询。
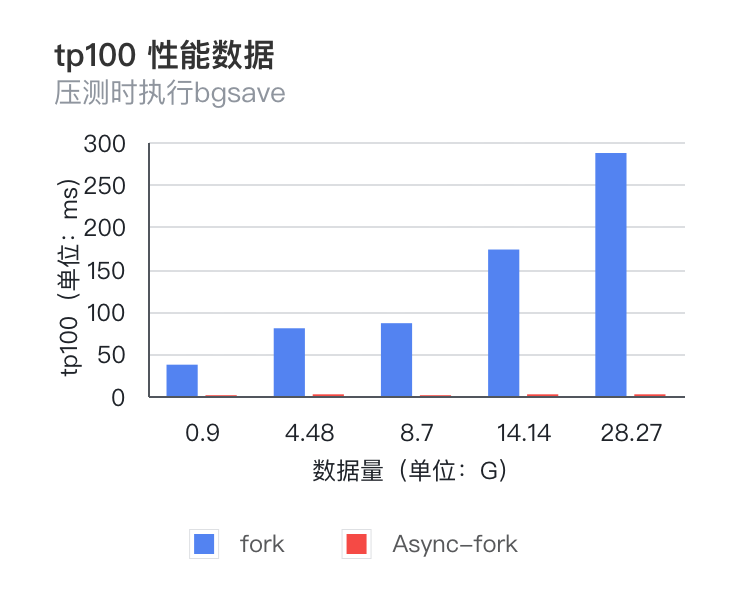
Async-Fork 特性在 Redis 中,在 AOF 文件重写、生成 RDB 备份文件以及主从全量同步过程中,都需要使用系统调用 Fork 创建一个子进程来获取内存数据快照,在 Fork() 函数创建子进程的时候,内核会把父进程的「页表」复制一份给子进程,如果页表很大,在现有常见操作系统中,复制页表的过程耗时会非常长,那么在此期间,业务访问 Redis 读写延迟会大幅增加。
自建 Redis 系统中,Redis-Server 通过优化并适配最新的支持 Async-Fork 特性的操作系统,极大的提升 Fork 操作性能:
Fork 命令耗时大幅减小,并且不随数据量增长而增长,基本稳定在 200 微秒左右;TP100 抖动得到明显改善,TP100 值也不随数据量增长而变大,基本在 1-2 毫秒左右;相比原生 Redis Fork 耗时减少 98%。日常运维中,添加从节点、主从切换、RDB 离线分析等常见运维操作均对业务无感知,不会造成业务性能抖动。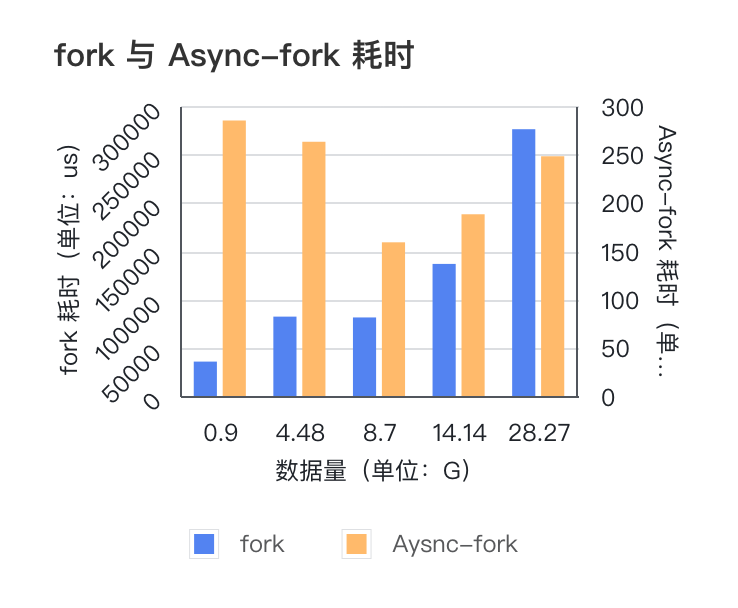 图片
图片
 图片
图片
注:该图表使用了双纵坐标详细内容可阅读《VLDB 顶会论文 Async-fork 解读与 Redis 实践》。
数据迁移为什么需要做数据迁移?主要是为了水平扩容,自建 Redis 将每个集群实例划分为固定数量的槽 slot,每个 Group 负责一部分槽,当进行水平扩容时,需要重新分配 slot 的分布,并且将一部分 slot 从原有节点迁移到新节点,同时将由 slot 负责的数据一起迁移到新节点。
数据迁移过程包括在源节点将 Key 对应的 Value 使用 Dump 命令进行序列化,然后将数据发送到目标节点,目标节点使用 Restore 命令将 Key 和 Value 存储到本地 Redis 中,最后源节点将该 Key 删除。
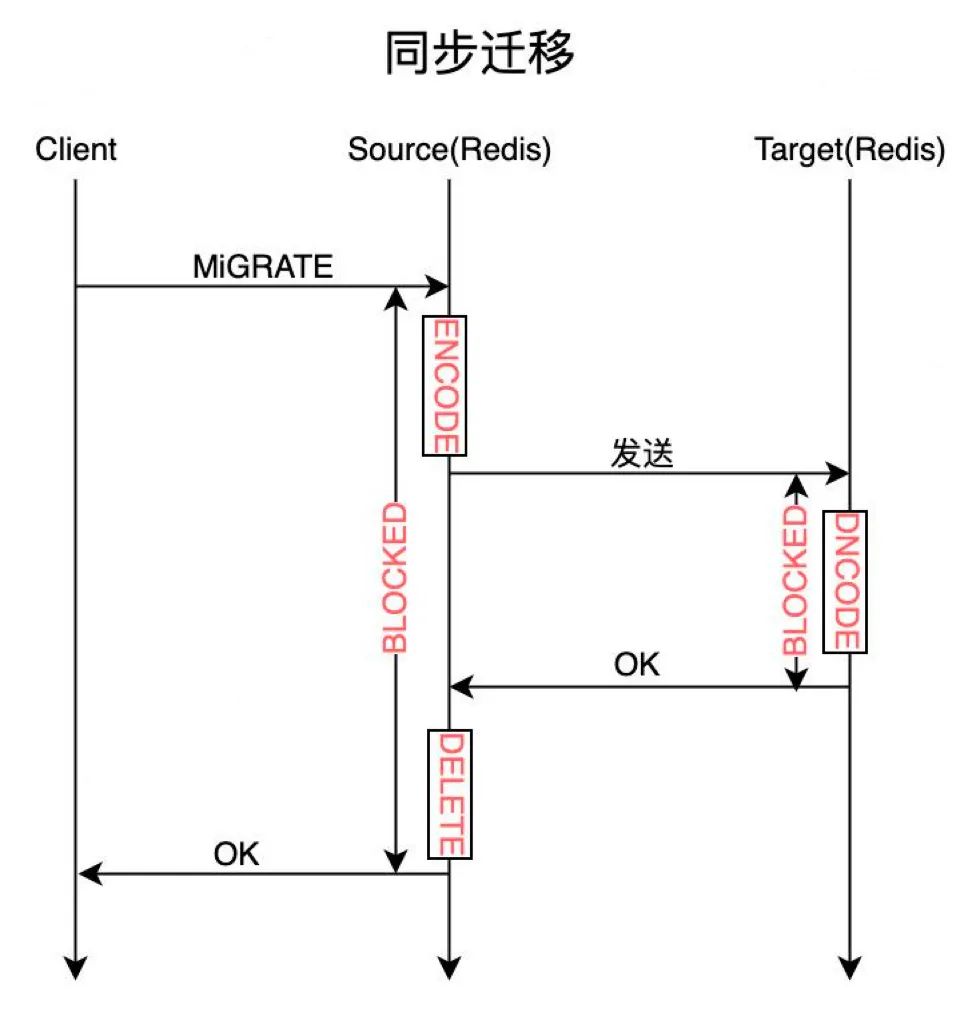
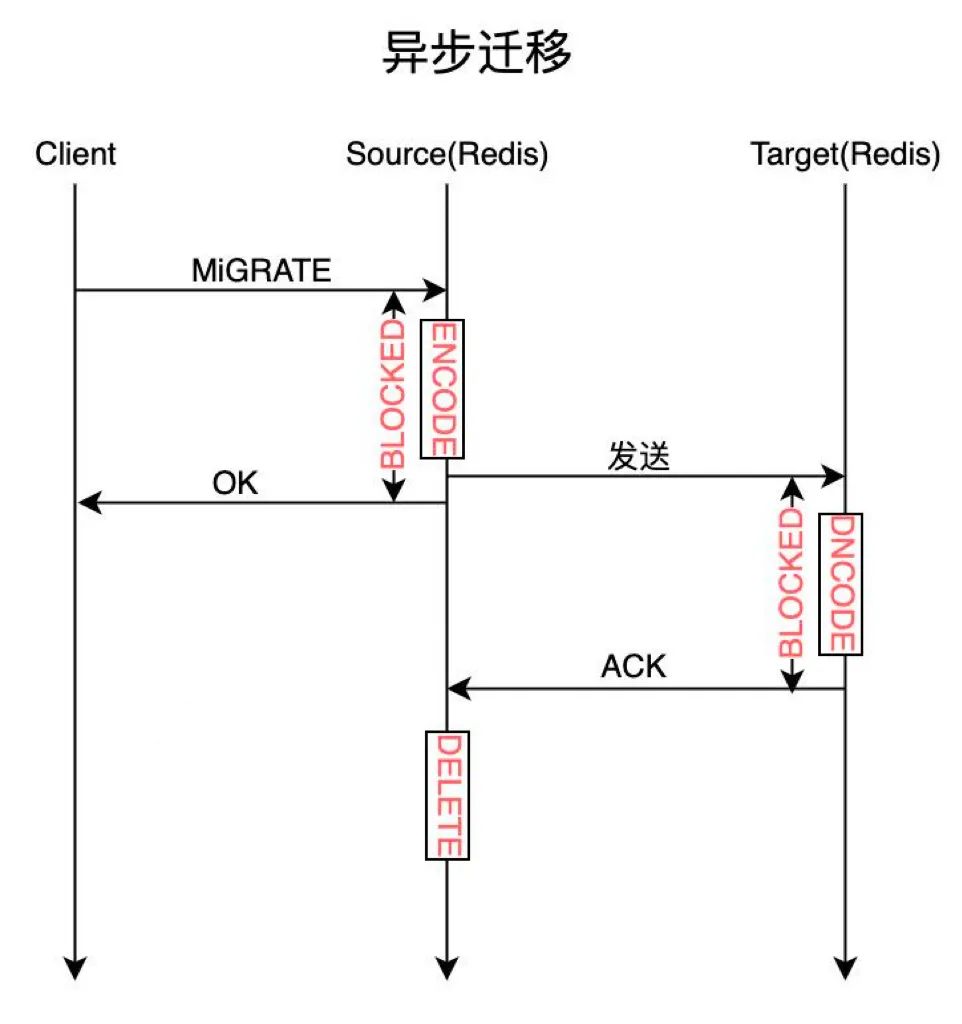
自建 Redis 支持同步迁移与异步迁移两种方式。
 图片
图片
 图片
图片
同步迁移:即在上述整个迁移过程中,源端的 Migrate 命令处于阻塞状态,直到目标端成功加载数据,并且返回成功,源节点删除该 Key 后,Migrate 命令才响应客户端成功。由于 Redis 数据操作是一个单线程模型,所有命令的处理的都在主线程中处理,因此 Migrate 命令会极大地影响其他正常业务的访问。
异步迁移:Migrate 命令仅阻塞 Dump 序列化数据、并且异步发送到目标节点,然后即返回客户端成功;目标节点接收到数据后,使用 Restore 命令进行保存,保存成功后,主动给源节点发送一个 ACK 命令,通知源节点将迁移的 Key 删除。异步迁移减少源端 Migrate 命令的阻塞时间,减少了 slot 迁移过程中对业务的影响。
三、自动化运维平台
自建 Redis 系统拥有功能完善的自动化运维平台。其主要功能包括:缓存实例自动化部署、快速水平扩容与垂直扩容、多维度资源管理、诊断与分析等。
运维平台架构
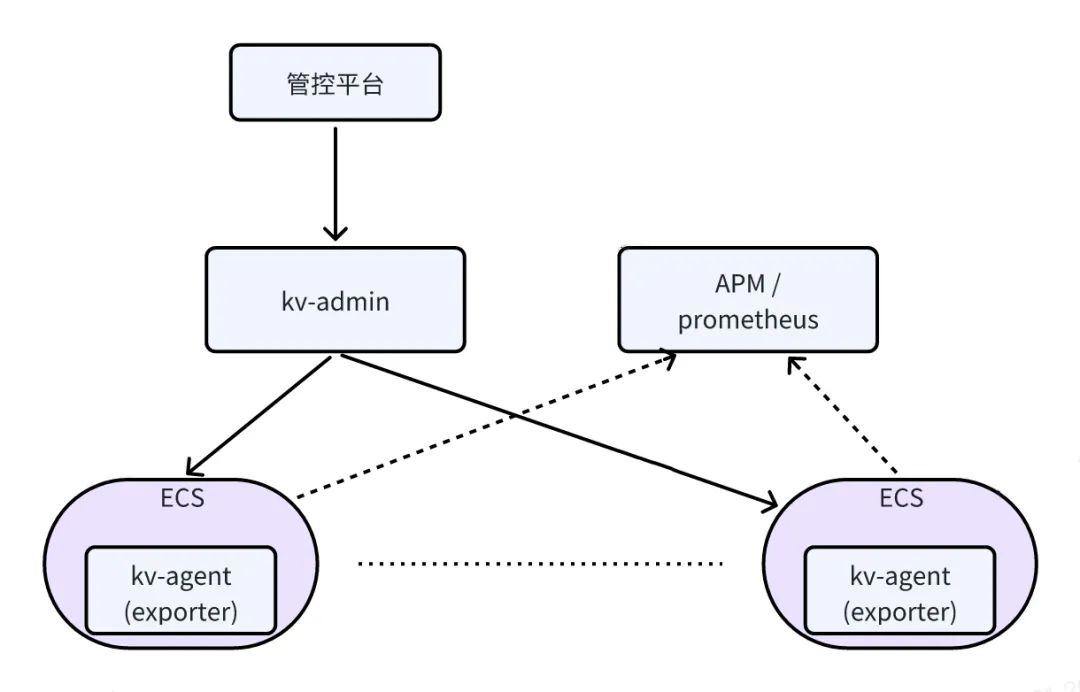
自建 Redis 自动化运维平台包括Redis 管控平台、Kv-Admin、Kv-Agent、Prometheus 等组件,部署架构如下图所示:
 图片
图片
Redis 管控平台是自建 Redis 综合运维管理平台,自建 Redis 的可视化操作均在 Redis 管控平台上完成,包括实例部署、扩容、数据迁移等在内的所有日常运维操作均可在管理平台上完成。
Kv-AdminKv-Admin 是自动化运维平台的核心组件,负责处理所有前端发送过来的请求,核心功能包括:
负责完成实例部署时任务调度、机器推荐、端口分配、SLB 推荐与绑定。实例列表展示、实例基本信息查询。数据离线分析与保存。资源池管理及生成资源报表。Kv-Agent每个 ECS 上会部署一个 Kv-Agent 组件,Kv-Agent 负责完成实例部署、实例启停等操作;基于心跳元数据的 Exporter 自动注册与解除;
同时,Kv-Agent 包含 Exporter 模块,负责 Redis-Server 节点的监控信息采集,然后将数据规范化后通过端点暴露给 Prometheus。
APM / PrometheusAPM 监控平台或者 Prometheus 负责从 Exporter 暴露的端点拉取监控数据;自建 Redis 监控与告警均接入公司 APM 平台。
实例自动化部署
一个缓存实例的部署非常复杂,涉及机器选择、配置文件准备、节点安装与启动、槽位分配、主从关系设置、SLB 分配与绑定、以及相关组件的部署等一系列动作。
自动化运维平台支持安装包版本管理,在部署页面选择合适的包版本、配置对应实例可用区、规格等基本信息后,一键操作即可完成 ConfigServer、Redis-Proxy、Redis-Server 等组件的部署,自动完成组件部署过程中涉及的上述机器推荐、配置文件准备、节点安装与启动等所有过程。
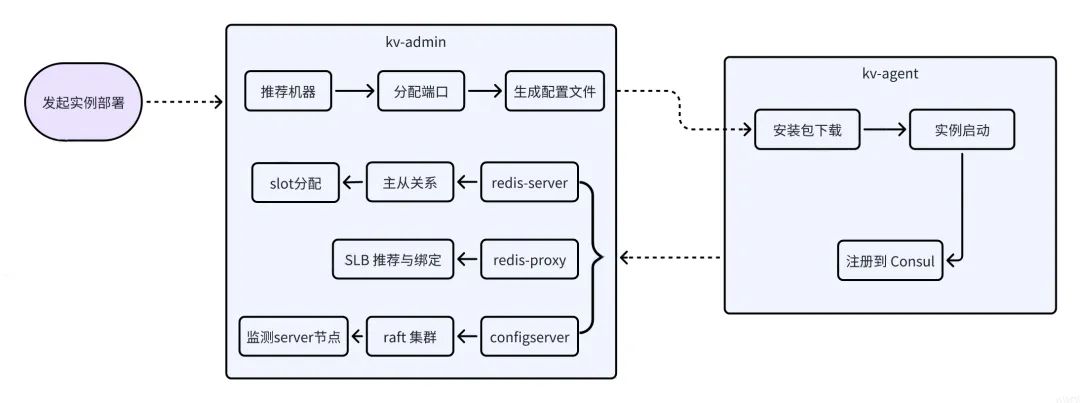
为了保证实例中所有组件的高可用,自动化部署过程中包含一些必要的部署规则:
ConfigServer 组件会部署在三个不同的可用区。避免同一个集群实例的多个 Redis-Server、Redis-Proxy 节点部署在相同的 ECS 上,每个 ECS 上可部署的同一个集群实例的 Server 或 Proxy 组件数量可配置。每个 ECS 最多分配总内存容量的 90%,预留一定的数据增长空间。根据 ECS 可用内存,优先推荐剩余可用内存多的 ECS。根据 Group 数量,自动均衡分配每个 Group 负责的 slot 数量。根据 SLB 近三天的流量峰值,自动绑定最优的 SLB。实例扩容
当业务数据增长导致实例内存使用率超过一定阈值后,根据单节点分配的最大内存、实例的 Group 数量等情况综合考虑,运维可选择为实例进行垂直扩容或者水平扩容。
垂直扩容,即动态修改单节点的 Maxmemory 参数,提高单节点的容量。
水平扩容,即增加实例的 Group 数量,对应增加主从节点数量,然后重新进行 slot 分配和对应的数据迁移动作。
一般来说,当单节点规格小于 4G 时,会优先考虑垂直扩容,简单快速,对业务无任何影响。
自动化运维平台支持方便的垂直扩容和水平扩容操作。
对于垂直扩容,运维平台支持批量调整实例 Redis-Server 节点的容量。
对于水平扩容,同实例初始部署一样,运维平台支持新增 Redis-Server 节点的自动化部署、主从关系设置等,同时支持按照实例总节点数重新自动均衡分配每个 Group 负责的 slot 数量,并自动完成数据迁移,数据迁移进度可视化。
资源管理
自建 Redis 运维平台目前管理的 ECS 超过数千台,运维平台支持 ECS 资源批量添加、资源分配、资源锁定、资源推荐等资源管理功能,以及提供资源利用率报表。
运维平台支持 ECS 可用内存的管理与分配,运维平台记录每台 ECS 的剩余可分配内存容量,Redis-Server 实例部署时,优先推荐剩余可分配内存多的 ECS,分配出去的 ECS 更新对应的可用内存容量。
Redis-Proxy 和 ConfigServer 部署时,优先推荐部署的实例数量较少的 ECS。
诊断与分析
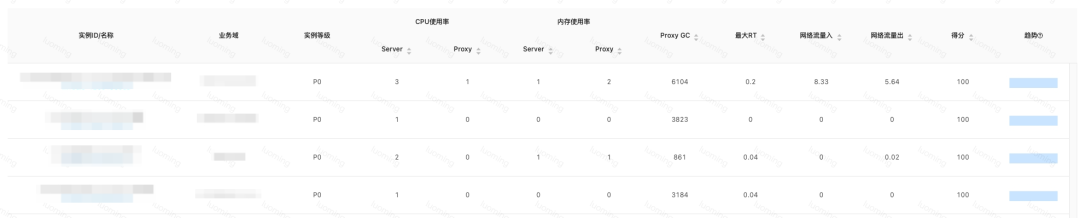
计算实例综合得分:运维平台通过分析所有实例关键监控指标前一天的峰值,再根据各项指标的权重,每天自动计算所有实例的得分,根据各实例的得分即可快速了解各实例的使用健康度。
参与计算得分的关键指标包括:Proxy CPU、Redis CPU、Redis 内存使用率、Proxy 占用内存、Proxy GC 次数、最大 RT、Redis 流入流量、Redis 流出流量等。
慢日志:运维平台支持 Redis-Server 记录的慢日志和 Redis-proxy 记录的慢日志查询。
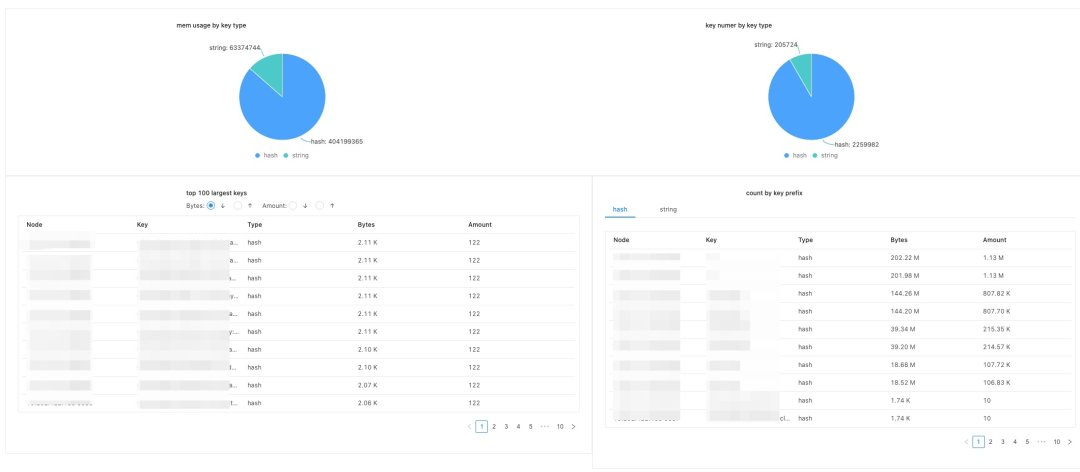
RDB 离线分析:运维平台支持生成 RDB 文件,并自动进行数据离线分析。分析结果包含 Top100 Value 最大的 Key 和元素个数最多的 Key;每种类型 Key,不同 Key 前缀包含的 Key 数量等。
 图片
图片
四、监控与告警
自建 Redis 系统接入 APM 监控平台,提供了各种维度的监控指标和告警功能,及时对异常情况进行预警,当出现问题时,也能帮助快速定位问题。
监控
ECS:CPU、系统 Load、内存、网络流量、网络丢包、磁盘 IO 等。
Proxy:QPS、TP999/TP9999/TP100、连接数、CPU、 内存、GC、Goroutine 数量等。
Server:CPU、内存、网络、连接数、QPS、Key 数量、命中率、访问 RT等。
告警
自建 Redis 包含大量的告警指标:
ECS CPU 使用率、内存使用率、系统 Load(5 分钟平均值)、流量。SLB 流量。Server、Proxy、ConfigServer 节点宕机。主节点缺失从节点、主节点可用区不一致、主从角色切换。五、稳定性治理
资源隔离
自建 Redis 目前所有组件都是部署在 ECS 上,为了提高资源利用率节约成本,大部分业务域的 Redis 集群都是混布的。自建 Redis 运维平台目前管理 ECS 超过数千台,接入的业务也涵盖营销、风控、算法、投放、社区、大数据等等,每个业务的实例等级、QPS、流量等指标各有差异,少数业务 Redis 可能存在突发写入流量高、Proxy CPU毛刺等现象,可能会引起相同 ECS 上其他实例性能抖动。
按标签分类:为了方便资源隔离与资源分配时管理,所有 ECS 资源按标签进行分类管理,针对特殊需求业务、大流量实例、通用资源池等划分不同的资源标签,实例部署时选择合适的标签、或者频繁出现告警时调整到对应资源池进行隔离,避免相互影响。
Proxy CPU 限制:为了防止单个 Redis-Proxy 进程抢占过多 CPU 资源,Redis-Proxy 支持配置 Golang GOMAXPROCS 参数来设置单个进程允许使用的最大 CPU 核数。
巡检
为了提前发现潜在的风险,除了日常告警外,我们支持自动巡检工具和巡检信息页面,建立了定期巡检机制。
实例综合得分排名:运维平台通过分析所有实例关键监控指标前一天的峰值,再根据各项指标的权重,每天自动计算所有实例的得分,在巡检信息页面进行展示,通过得分排序即可快速发现风险实例。
 图片
图片
ECS 资源大盘:实时展示所有 Redis-Proxy 和 Redis-Server 使用 ECS 的重要指标,通过排序即可快速浏览各 ECS 各项重要指标,如 CPU 使用率、内存使用率、IOPS 使用率、磁盘读取/写入、上传/下载带宽等。
自动巡检工具:定期检查所有实例的配置、节点数量等基本信息,对于如从节点缺失、可用区不一致、节点配置不一致等异常情况进行提示。
故障演练
为了提高自建 Redis 系统在异常场景下的可用性、检验自建 Redis 系统在各异常场景的恢复时间,我们不定期进行多次故障演练。
故障演练涵盖所有组件在ECS、网络、磁盘等出现故障的场景,以及多个组件组合同时出现这些故障的场景。
经过故障演练检验,自建 Redis 系统 Redis-Server 主节点故障恢复时间 12s,Redis-Proxy 故障业务恢复时间 5s 内。
六、总结
本文详细介绍了自建 Redis 架构和现有一些重要特性,我们还在持续不断地迭代优化和丰富支持的特性,为我们的业务提供一个功能更强大、性能更优异的分布式缓存系统。未来我们还会迭代的方向可能包括且不限于:
目前 Redis-Server 为了兼容云上版本和分布式架构做了很多定制化,所以未使用最新社区版本,未来会升级到最新的社区版本如 7.0。热 Key 访问一直是 Redis 使用中对业务影响较大的一个问题,未来我们考虑支持热 Key 统计与读热 Key 本地缓存。Golang 版本 Proxy 在高 QPS 请求时,GC 是性能提升的一个瓶颈,未来考虑使用 Rust 重构 Proxy。