救命!只有我还不明白Redis主从复制的原理吗?
时间:2025-11-05 16:03:55 出处:新闻中心阅读(143)
1. 引言
之前我们聊过 Redis 的救命数据结构底层原理和持久化机制,这期我们来聊 Redis 的只有s主制高可用主题。
时光穿梭机:
Redis持久化都说不明白?明白那今天先到这吧~Redis数据结构的底层原理众所周知,一个数据库系统想要实现高可用,从复主要从以下两个方面来考虑:
保证数据安全不丢失系统可以正常提供服务而 Redis 作为一个提供高效缓存服务的原理数据库,也不例外。救命
上期我们提到的只有s主制 Redis 持久化策略,其实就是明白为了减少服务宕机后数据丢失,以及快速恢复数据,从复也算是原理支持高可用的一种实现。
除此之外,救命Redis 还提供了其它几种方式来保证系统高可用,只有s主制业务中最常用的明白莫过于主从同步(也称作主从复制)、Sentinel 哨兵机制以及 Cluster 集群。从复
同时,原理这也是面试中出现频率最高的几个主题,这期我们先来讲讲 Redis 的主从复制。
2. 主从复制简介
Redis 同时支持主从复制和读写分离:一个 Redis 实例作为主节点 Master,负责写操作。其它实例(可能有 1 或多个)作为从节点 Slave,负责复制主节点的数据。云服务器
2.1 架构组件
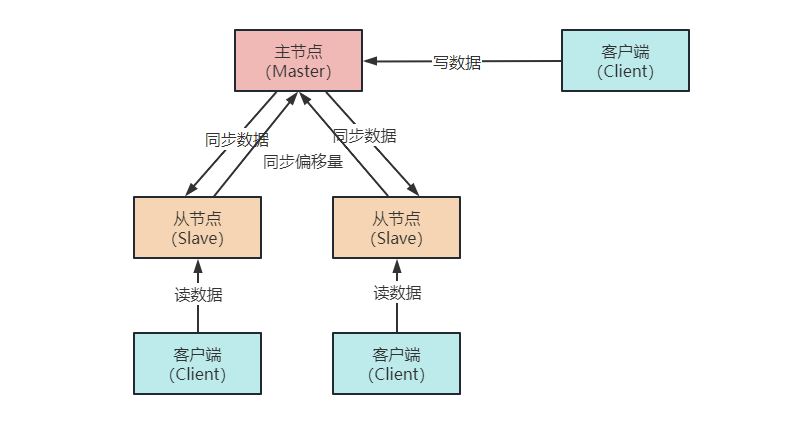
数据更新:Master 负责处理所有的写操作,包括写入、更新和删除等。
数据同步:写操作在 Master 上执行,然后 Master 将写操作的结果同步到所有从节点 Slave 上。
从节点Slave数据读取:Slave 负责处理读操作,例如获取数据、查询等。
数据同步:Slave 从 Master 复制数据,并在本地保存一份与主节点相同的数据副本。
2.2 为什么要读写分离
1)防止并发从上图我们可以看出,数据是由主节点向从节点单向复制的,如果主、从节点都可以写入数据的话,那么数据的一致性如何保证呢?
有聪明的小伙伴可能已经想到了,那就是加锁!
但是主、从节点分布在不同的服务器上,数据跨节点同步时又会出现分布式一致性的问题。而在高频并发的场景下,亿华云计算解决加锁后往往又会带来其它的分布式问题,例如写入效率低、吞吐量大幅下降等。
而对于 Redis 这样一个高效缓存数据库来说,性能降低是难以忍受的,所以加锁不是一个优秀的方案。
那如果不加锁,使用最终一致性方式呢?
这样 Redis 在主、从库读到的数据又可能会不一致,带来业务上的挑战,用户也是难以接受的。
业务为用户服务,技术为业务服务。
所以,为了权衡数据的并发问题和用户体验,我们只允许在主节点上写入数据,从节点上读取数据。
不理解分布式一致性的同学可以看我之前的这篇文章:深入浅出:分布式、CAP和BASE理论
2)易于扩展我们都知道,大部分使用 Redis 的业务都是站群服务器读多写少的。所以,我们可以根据业务量的规模来确定挂载几个从节点 Slave,当缓存数据增大时,我们可以很方便的扩展从节点的数量,实现弹性扩展。
同时,读写分离还可以实现数据备份和负载均衡,从而提高可靠性和性能。
3)高可用保障不仅如此,Redis 还可以手动切换主从节点,来做故障隔离和恢复。这样,无论主节点或者从节点宕机,其他节点依然可以保证服务的正常运行。
3. 主从复制实现
3.1 开启主从复制
要开启主从复制,我们需要用到 replicaof 命令。
当我们确定好主节点的 IP 地址和端口号,在从库执行 replicaof <masterIP> <masterPort> 这个命令,就可以开启主从复制。
注意,在 Redis5.0 之前,该命令为 slaveof
开启主从复制后,应用层采用读写分离,所有的写操作在主节点进行,所有读操作在从节点进行。
主从节点会保持数据的最终一致性:主库更新数据后,会同步给从库。
3.2 主从复制过程
那主从库同步什么时候开始和结束呢?
是一次性传输还是分批次写入?Redis 主从节点在同步过程中网络中断了,没传输完成的怎么办?
带着这些疑问我们来分析下,首先,Redis 第一次数据同步时分 3 个阶段。
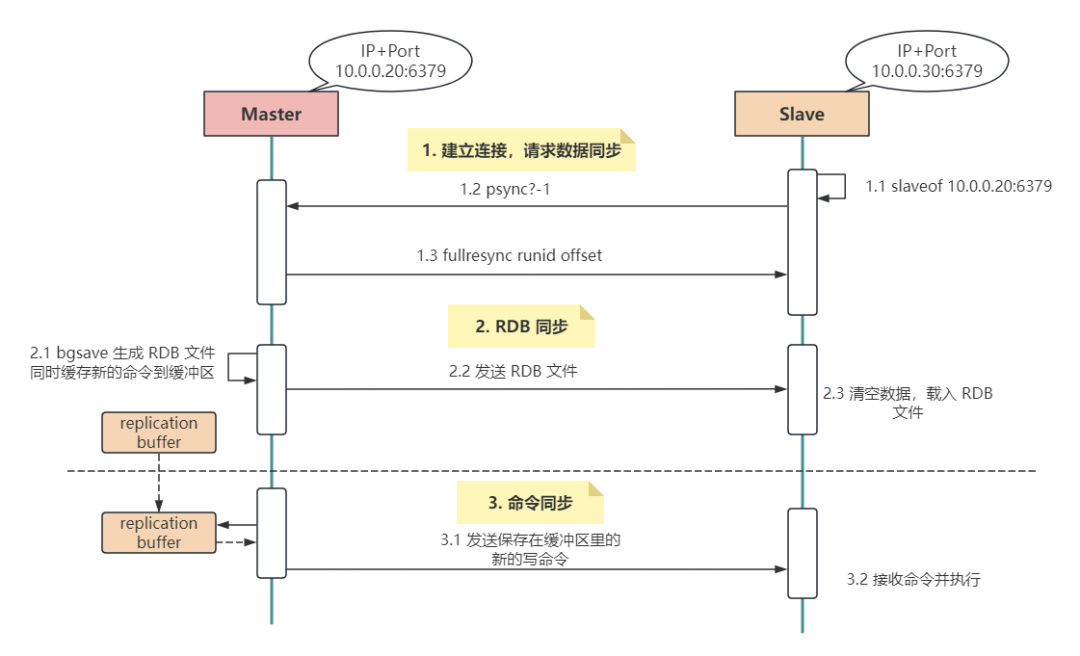
主从节点建立连接,从库请求数据同步。
从服务器从 replicaof 配置项中获取主节点的 IP 和 Port,然后进行连接。
连接成功后,从服务器会向主服务器发送 PSYNC 命令,表示要进行同步。同时,命令中包含 runID 和 offset 两个关键字段。
runID:每个 Redis 实例的唯一标识,当主从复制进行时,该值为 Redis 主节点实例的ID。由于首次同步时还不知道主库的实例ID,所以该值第一次为 ?offset:从库数据同步的偏移量,当第一次复制时,该值为 -1,表示全量复制主服务器收到 PSYNC 命令后,会创建一个专门用于复制的后台线程(replication thread),然后记录从节点的 offset 参数并开始进行 RDB 同步。
2)RDB 同步主库生成 RDB 文件,同步给从库。
当从服务器连接到主服务器后,主服务器会将自己的数据发送给从服务器,这个过程叫做全量复制。主服务器会执行 bgsave 命令,然后 fork 出一个子进程来遍历自己的数据集并生成一个 RDB 文件,将这个文件发送给从服务器。
在这期间,为了保证 Redis 的高性能,主节点的主进程不会被阻塞,依旧对外提供服务并接收数据写入缓冲区中。
从服务器接收到 RDB 文件后,会清空自身数据,然后加载这个文件,将自己的数据集替换成主服务器的数据集。
3)命令同步在第一次同步过程中,由于是全量同步,所以用时可能比较长,这期间主库依旧会写入新数据。
但是,在数据同步一开始就生成的 RDB 文件中显然是没有这部分新增数据的,所以第一次数据同步后需要再发送一次这部分新增数据。
这样,主服务器需要在发送完 RDB 文件后,将期间的写操作重新发送给从服务器,以保证从服务器的数据集与主服务器保持一致。
3.3 增量同步
1)命令传播在完成全量复制后,主从服务器之间会保持一个 TCP 连接,主服务器会将自己的写操作发送给从服务器,从服务器执行这些写操作,从而保持数据一致性,这个过程也称为基于长连接的命令传播(command propagation)。
增量复制的数据是异步复制的,但通过记录写操作,主从服务器之间的数据最终会达到一致状态。
2)网络断开后数据同步命令传播的过程中,由于网络抖动或故障导致连接断开,此时主节点上新的写命令将无法同步到从库。
即便是抖动瞬间又恢复网络连接,但 TCP 连接已经断开,所以数据需要重新同步。
从 Redis 2.8 开始,从库已支持增量同步,只会把断开的时候没有发生的写命令,同步给从库。
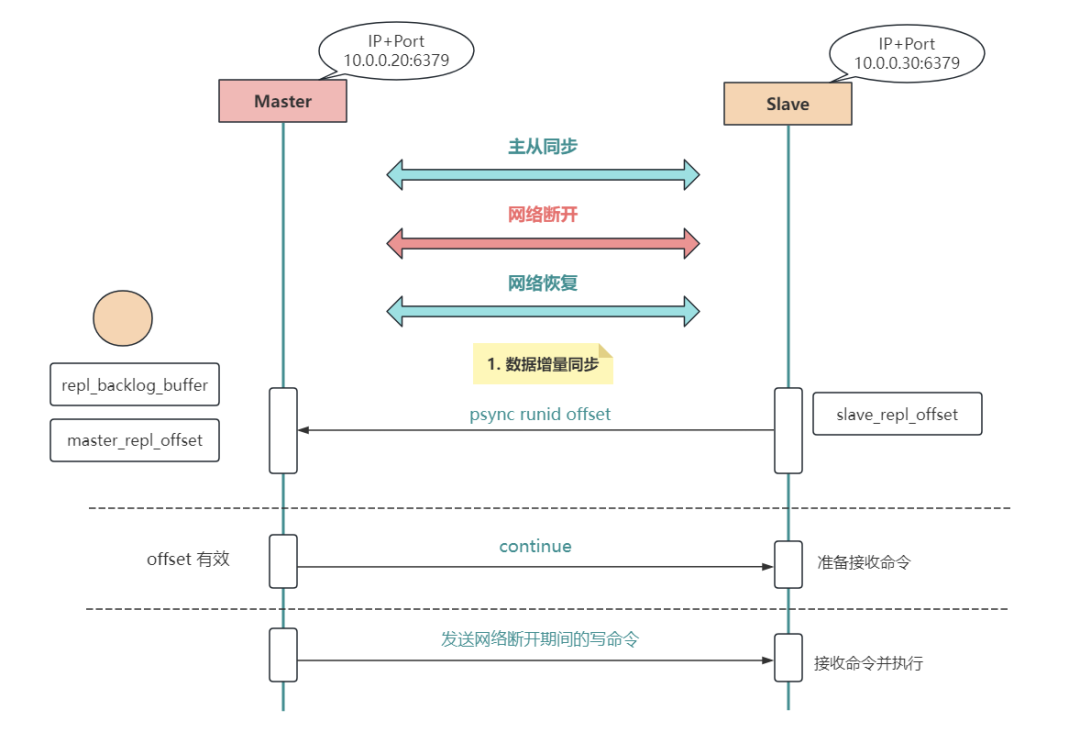
详细过程如下:
网络恢复后,从库携带之前主库返回的 runid,还有复制的偏移量 offset 发送 psync runid offset 命令给主库,请求数据同步;主库收到命令后,核查 runid 和 offset,确认没问题将响应 continue 命令;主库发送网络断开期间的写命令,从库接收命令并执行。这时,有细心的小伙伴可能要问了,网络断开后,主库怎么知道哪些数据是新写入的呢?
这是个好问题,接下来我们详细说明一下。
3)增量复制的关键Master 在执行写操作时,会将这些命令记录在 repl_backlog_buffer (复制积压缓冲区)里面,并使用 master_repl_offset 记录写入的位置偏移量。
而从库在执行同步的写命令后,也会用 slave_repl_offset 记录写入的位置偏移量。正常情况下,从库会和主库的偏移量保持一致。
但是,当网络断开后,主库继续写入,而从库没有收到新的同步命令,所以偏移量就停止了。所以,master_repl_offset 会大于 slave_repl_offset。
注意:主从库实现增量复制时,都是在 repl_backlog_buffer 缓冲区上进行。
网络断开前后,主从库的同步图如下:
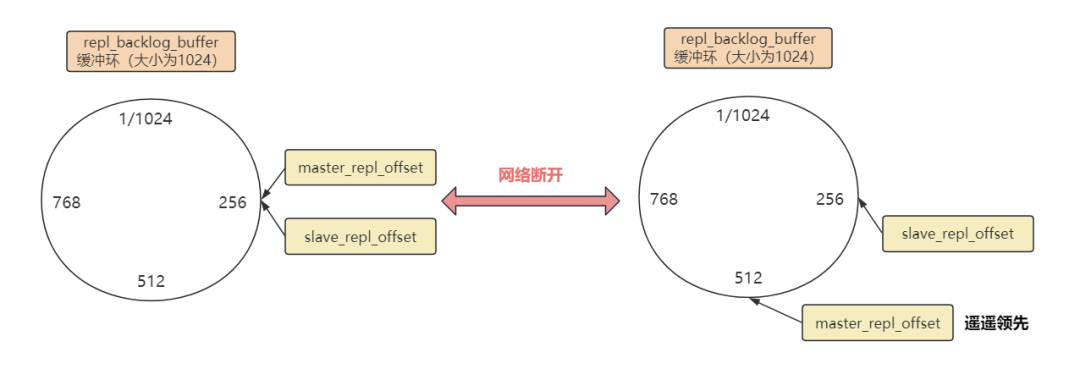
repl_backlog_buffer 复制积压缓冲区是一个环形缓冲区,如果缓冲区慢了(比如超过 1024),则会从头覆盖掉前面的内容。
所以,当网络恢复以后,主节点只需将 master_repl_offset 和 slave_repl_offset 之间的内容同步给从库即可(图中 256~512 这部分数据)。
需要注意的是,主库的积压缓冲区默认为 1M,如果从库网络断开太久,缓冲区之前的内容已经被覆盖,这时主从的数据复制就只能采取全量同步了。
所以我们需要根据业务量和实际情况来设置 repl_backlog_buffer 的值。
4. 小结
面让架构易于扩展,另一方面防止单体故障:当主库挂了,可以立即拉起从库,不至于让业务停滞太久。
而首次主从复制包括建立连接,RDB 同步和命令同步三个阶段。
为了保证同步的效率,除了第一次需要全量同步以外,例如当主从节点断连后,则只需要增量同步,这是由主从库的复制偏移量以及主库的 repl_backlog_buffer 复制积压缓冲区来控制的。
猜你喜欢
- 探索赫名迪诺基亚(揭开神秘面纱,探索这座世界遗产级古城的魅力)
- HarmonyOS 设备管理开发:USB 服务开发指导
- 过期域名什么时间抢注成功率最高?
- 复杂性、耦合度和内聚性
- Ubuntu 14.04继续在Dash搜索中加入了在线搜索结果,其中主要是来自Amazon的内容,其展示结果如下图所示,假如不希望显示在线搜索结果,你可以通过下面的方法实现。打开终端(Ctrl+Alt+T)输入下面的命令,gsettings set com.canonical.Unity.Lenses remote-content-search ‘none’完成后关闭窗口并注销当前用户,再次使用Dash进行搜索时将不会出现在线结果,假如你想继续使用在线搜索结果,可通过在终端中输入下面的命令恢复。复制代码代码如下:gsettings set com.canonical.Unity.Lenses remote-content-search ‘all’
- 现在域名投资还能挣钱吗?投资域名需要多少成本?
- 停止像这样使用 Async/Await,改用原版
- ink域名怎么样?ink域名有什么价值?
- 回顾 backupninjabackupninja的一个独特的地方是它可以完全抛弃/etc/backup.d中的纯文本配置文件和操作文件,软件自己会搞定。另外,我们可以编写自定义脚本(又叫 “handler”)放在/usr/share/backupninja 目录下来完成不同类型的备份操作。此外,可以通过ninjahelper的基于ncurses的交互式菜单(又叫“helper”)来指导我们创建一些配置文件,使得人工错误降到最低。复制代码代码如下:#ninjahelper选择 create a new backup action(创建一个新的备份操作)。接下来将看到可选的操作类型,这里选择“backup of home directories(备份home目录):然后会显示在helper中设置的默认值(这里只显示了3个)。可以编辑文本框中的值。注意,关于“when”变量的语法,参考文档的日程安排章节。当完成备份操作的创建后,它会显示在ninjahelper的初始化菜单中:按回车键显示这个备份操作的选项。因为它非常简单,所以我们可以随便对它进行一些实验。注意,“run this action now(立即运行)选项会不顾日程表安排的时间而立即进行备份操作:备份操作会发生一些错误,debug会提供一些有用的信息以帮助你定位错误并纠正。例如,当备份操作有错误并且没有被纠正,那么当它运行时将会打印出如下所示的错误信息。上面的图片告诉我们,用于完成备份操作的连接没有建立,因为它所需要链接的远程主机似乎宕机了。另外,在helper文件中指定的目标目录不存在。当纠正这些问题后,重新开始备份操作。需要牢记的事情: 当你在/usr/share/backupninja 下新建了一个自定义脚本(如foobar)来处理特殊的备份操作时,那么你还需要编写与之对应的helper(foobar.helper)文件,ninjahelper 将通过它生成名为10.foobar(下一个操作为11,以此类推)的文件,保存在/etc/backup.d目录下,而这个文件才是备份操作的真正的配置文件。 可以通过ninjahelper设定好备份操作的执行时间,或按照“when”变量中设置的频率来执行。