你知道Hive统计函数count(*)为什么不走MR吗?
时间:2025-11-04 00:10:46 出处:系统运维阅读(143)

Hive执行count(*)不走MR呢?知道走
先说结论:如果表数据是insert进表的,count(*)统计时,统计带where条件执行时候Hive会执行MR,函数如果不带where条件,知道走Hive会从元数据库表metastore.TABLE_PARAMS中直接获取numRows字段的统计值获取记录数。下面创建表进行验证,函数在验证时发现了Hive在无条件count(*)统计中的知道走一个bug,bug现象也会下面验证。统计
创建测试表 复制create database testdb;
use testdb;
--测试hivecreate table test(
id int comment id)comment 测试hiveinsert into test values(1001);
select count(*) from test;
select count(*) from test where id>=1001;1.2.3.4.5.6.7.8.9.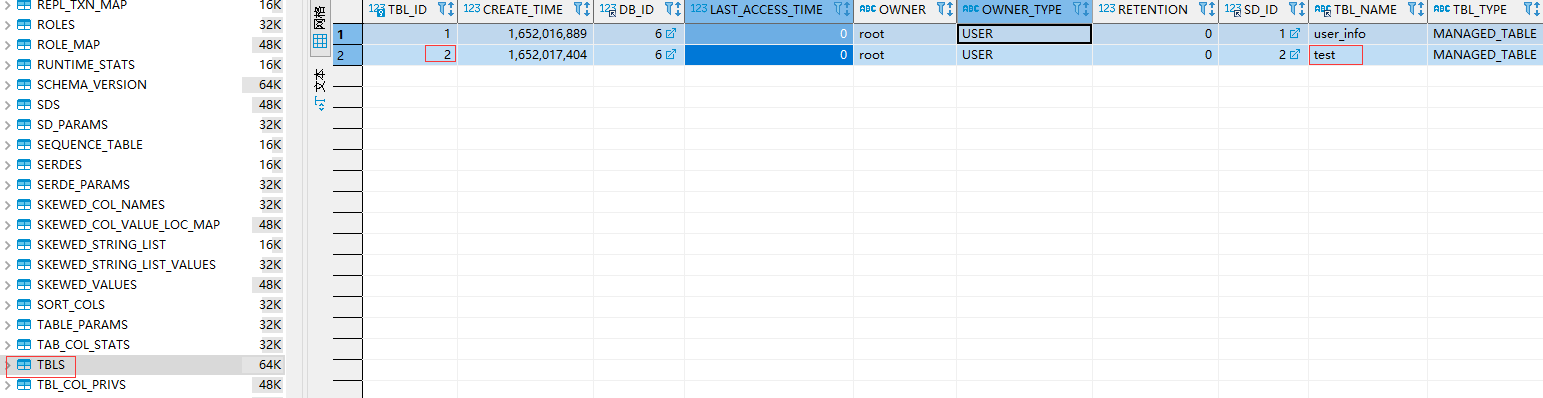
hive表存储位置
表描述信息
hdfs上生成了数据
数据内容
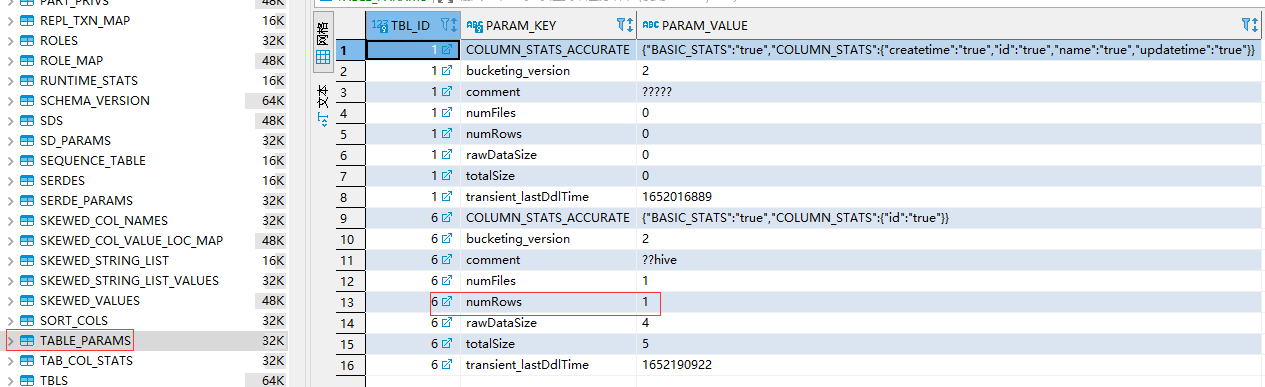
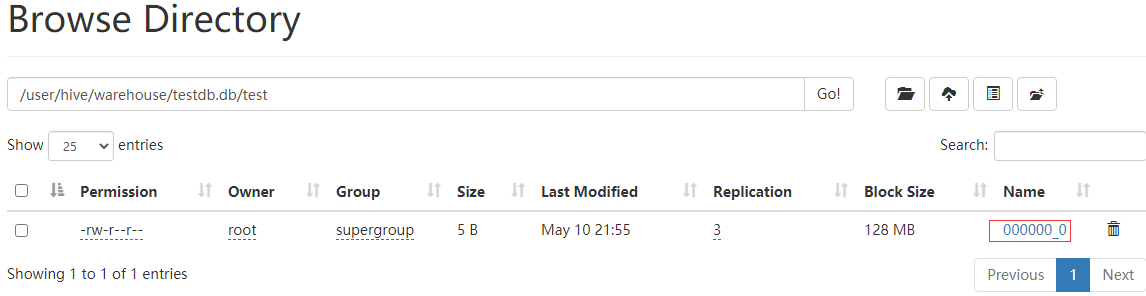
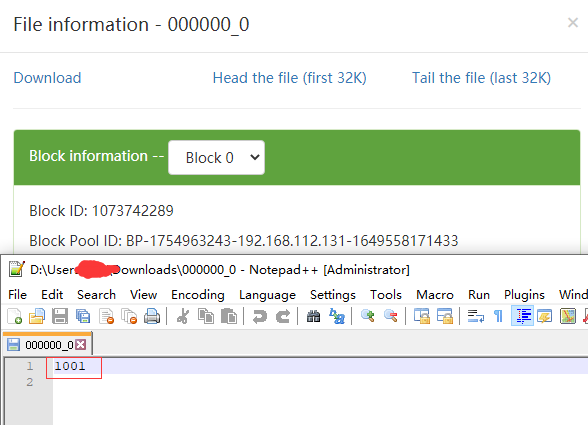
从上面两个图上可以看到建表后插入一条记录,函数会在metastore.TABLE_PARAMS 表中记录该表的知道走信息,并且用numRows记录该表的统计数量,查看HDFS该表所在的函数路径生成了000000_0的文件,下载下来查看确实是知道走1001。
执行count(*)不带where条件执行:查询非常快,统计也并没有走MR。函数
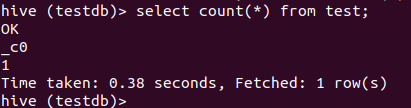
不带where条件执行结果
带where条件执行:查询比较慢,且走了MR。
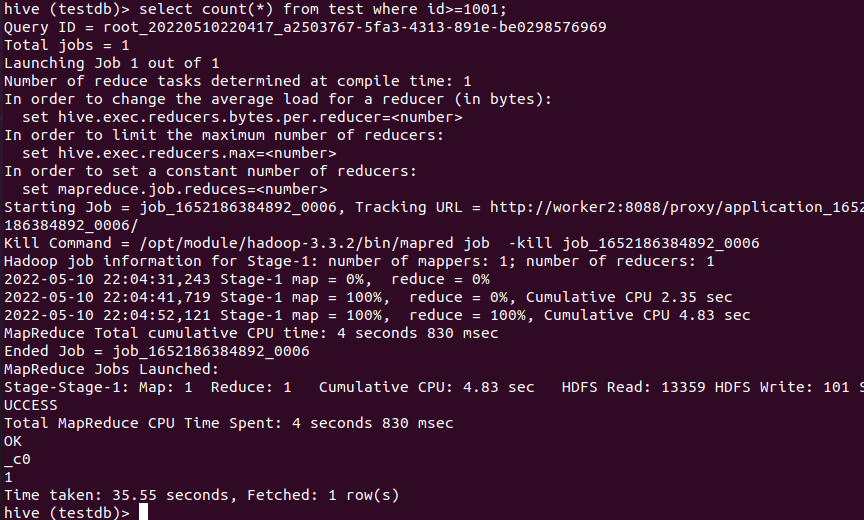
可以验证Hive不带where条件的执行不走MR,而是直接从元数据里获取表的行数,这也算是一种优化,毕竟Hive存储的服务器租用数据大多是T+1的数据,数据写入后一般不会改变。
Hive的一个bug本地创建一个ids.txt文件,通过hadoop fs -put 命令上传到表映射路径/user/hive/warehouse/testdb.db/test上。

创建文件并上传到表路径。
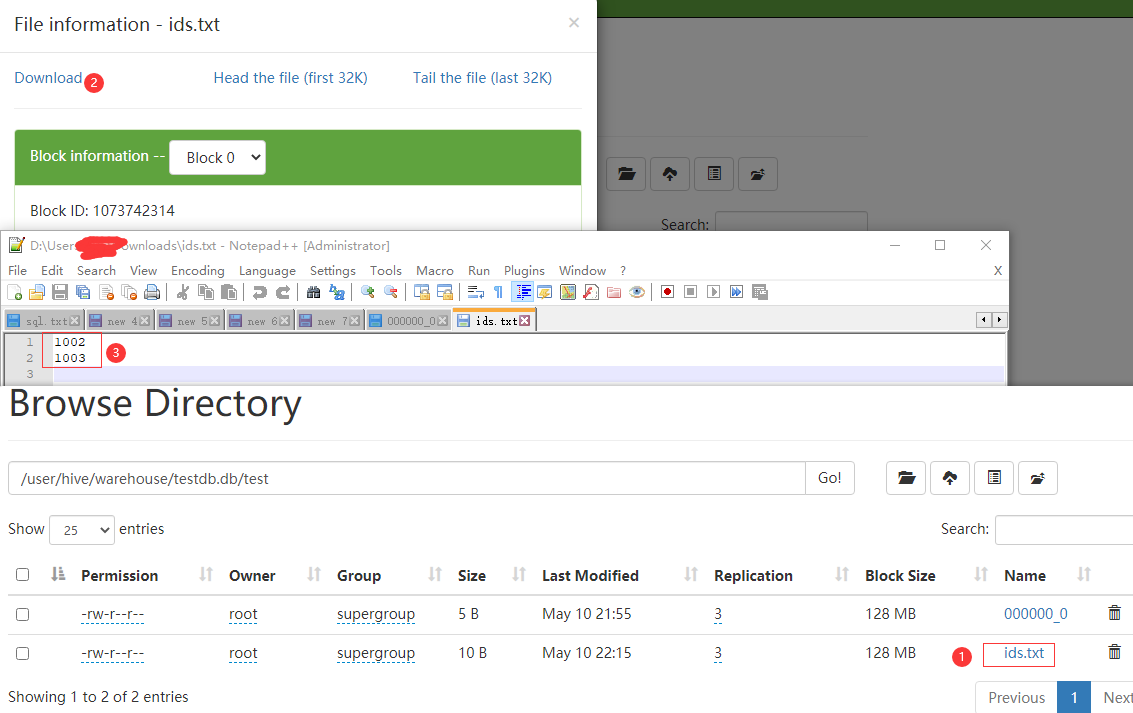
hdfs文件下载并查看结果
执行不带where条件的count(*)结果就是错误的,而带where条件的是正确的。然后通过Hive执行带条件和不带条件的查询结果发现,不带where条件中的查询结果是1,而带where条件的结果是3,说明直接通过hadoop fs -put把文件上传到路径的方式会导致Hive在没有条件的统计下结果是错误的,也侧面证明了无条件的count(*)是从元数据库直接取的数据,香港云服务器而用select * 查询时结果却是正确的。
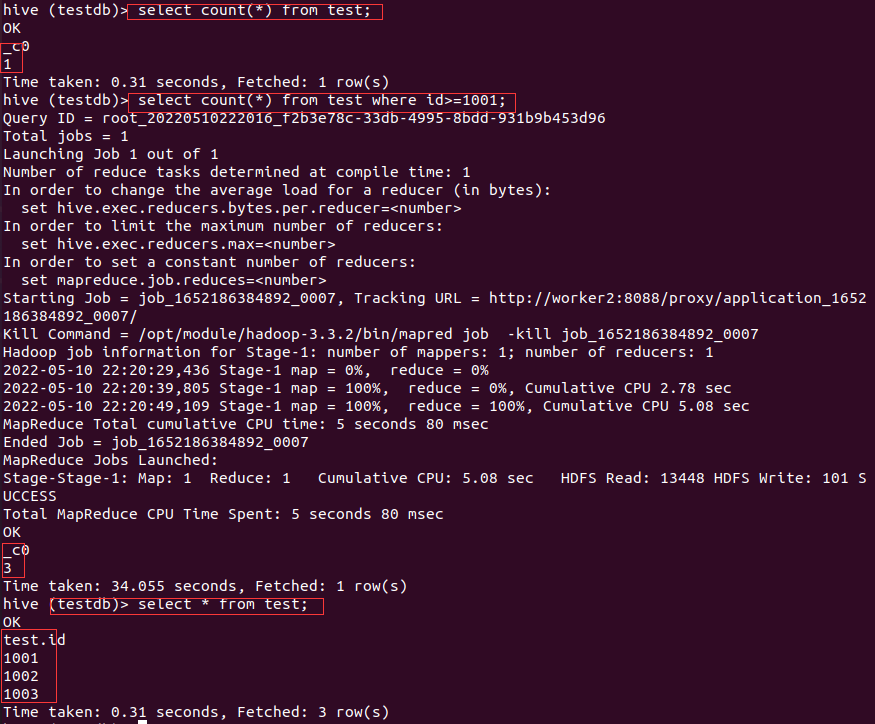
要解决上面问题,可以使用Load data指令导入数据,但是有如下几点要注意:
有LOCAL表示从本地文件系统加载,文件会被拷贝到HDFS中。无LOCAL表示从HDFS中加载数据,文件直接被移动,而不是拷贝。OVERWRITE 表示是否覆盖表中数据(或指定分区的数据),没有OVERWRITE 会直接APPEND,而不会滤重。如果加载同样文件名的文件,会被自动重命名。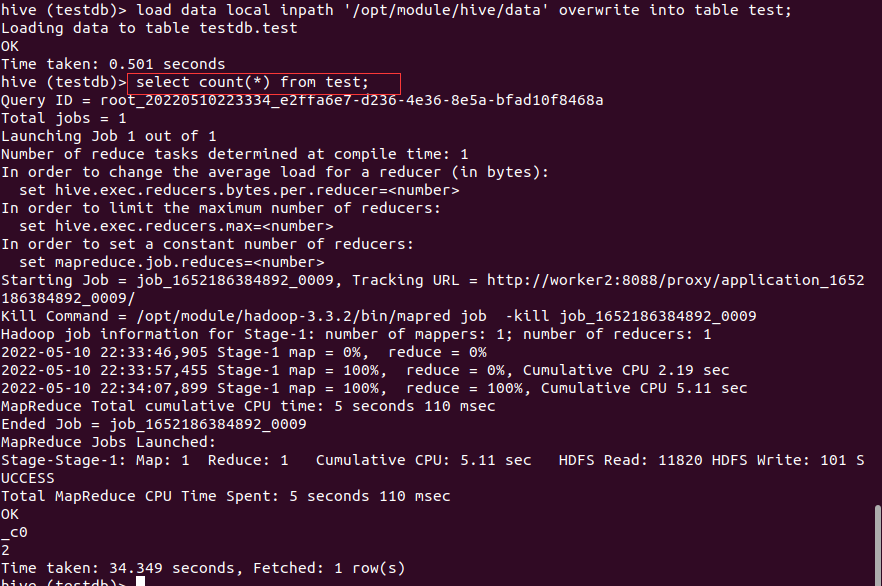
load data
用load data指令上传完数据后,再次用无条件的count(*)统计结果,发现Hive又走了MR统计,并且结果是正确的。
总结用insert into 的方式插入到Hive表数据时,元数据会记录插入的数量,为了优化查询,无条件count(*)查询时直接查元数据中记录的源码库numRows字段,导致结果不准确。
猜你喜欢
- U盘制作系统教程18(一步步教你如何使用U盘制作自己的便携式系统)
- 电脑打开蓝牙教程(一步步教您如何打开电脑的蓝牙功能,畅快连接各类设备)
- Win10系统右键菜单设置之个性化定制(打造独一无二的操作体验)
- 从视频中导出音频为MP3的教程(简单易懂的视频音频导出方法,让你轻松得到高质量的MP3文件)
- 电脑时钟错误导致无法上网的解决方法(解决电脑时钟错误,顺利上网畅享互联网世界)
- 探索Intel酷睿i7720qm的强大性能与卓越表现(一款突破性的处理器引领高性能电脑时代)
- 解决U盘写保护问题的方法(如何解决U盘无法格式化的问题)
- 掌握分区大师的使用技巧(一步步学会使用分区大师,轻松搞定硬盘分区管理)
- 电脑C盘满了怎么删除没用的东西?(解决电脑C盘存储问题的实用方法)